
Всем привет, сегодня речь пойдет о самой на первый взгляд такой простой теме как сбор информации.
Обратимся к теории.
Сбор информации заключает в себе получение большого количества данных о цели, которые пригодятся в использовании в дальнейшем. В данной статье мы будем рассматривать сбор информации о целевом веб ресурсе, инструменты которые позволяют собрать информацию, некоторые техники. Так вот, как вы наверняка знаете сбор информации делится на 2 этапа. Это активный и пассивный. Во время пассивного сбора наша цель даже не подозревает о действиях которые мы осуществляем(т.е. не знает что мы собираем информацию о ней). Чаще всего этот этап проходит при сборе с сторонних ресурсов(к примеру с google). А при активном сканировании вы уже взаимодействуете с целью(ищите открытые порты).
План сбора информации.
В течении всей статьи будем приддерживатся простенького плана в котором мы из пассивного сбора информации плавно переходим в активный:
Для тех кто ни разу не имел дела с дорками поясняю. Это специальные параметры поиска вернее сказать что-то вроде дополнительных опций и ограничений вывода при осуществлении запроса. Перейдем к делу.
Когда вы осуществляете запрос в гугл то в ответ видите миллионы различных ресурсов. Допустим я хотел бы научится взламывать wifi и прописал в строке поиска

Вывело 120000 доступных результатов. Но что если мы введем

Теперь количество результатов снизилось. Оператор site как бы говорит "искать информацию на данном сайте". А что если я хотел бы прочитать какие-либо файлы определенного формата. К примеру .pdf

Вы правильно поняли если предположили что filetype в качестве результата выдает файлы определенного формата. Допустим я хотел бы поискать какие-либо такстовые файлы. Тогда просто объеденим

Как видим мы нашли файл robots.txt
Наверное каждый из нас когда-либо искал уязвимые к SQL инъекции ресурсы используя дорки. Так вот давайте найдем сайты с следующим текстом в URL: .php?id=

А теперь попробуем найти данные в заголовке

Уметь искать информацию с использованием дорков очень полезно. Так как на пассивный поиск без использования прочих поисковиков уйдет немало времени.
Нашему взору представляется очень много информации. Если повезет то можно и увидеть email и имя которые были указаны при регистрации DNS. А если мы введем IP вместо доменного имени, то получаем диапазон ip адресов

Для автоматизации сбора информации существует целый фреймворк - recon-ng
<photo>
Вообще recon-ng уже входит в состав Kali. Давайте найдем поддомены google.ru(не реклама)

Используя сервисы описанные выше и инструменты которые присутствуют в статье, можно получить уйму информации. Но также ее нужно отсортировать. Для этого нам понадобится Maltego. Его уже описывали на форуме - здесь.
CMS. Чаще всего cms можно опеределить заглянув в meta тегв коде страницы целевого веб ресурса.

Также определить cms можно сервисом 2ip. Вот пример определения cms одного веб сайта


Чтобы про сканировать нужный вам порт существует такая опция как -p. Пример использования

Теперь попробуем узнать ОС целевой системы. На этот случай nmap обладает опцией -O

А для определения версий ОС и ПО при этом получить много полезной информации можно использовав данную команду

С этим мы определились. Перейдем к активным хостам. У нас имеется полученный ранее диапазон. Воспользуемся fping

Как видим живых хостов много. В итоге у меня получился огромный список живых хостов.
DNS. Попробуем получить информацию из mx и ns записей.
Для определения ns записей пишем следующее
Где google.com - ваш домен. Для mx записей картина такая же как и была
Вывод.
Недавно на форуме появилась статья от @Ondrik8 в которой описаны некоторые инструменты для сбора информации и пентеста веб ресурсов. Прочитать можно - тут
Так вот, сбор информации является немаловажной частью в пентесте web ресурсов, и даже не именно web ресурсов а вообще систем, сетей и прочего. Всем спасибо! До встречи в следующей части)
Обратимся к теории.
Сбор информации заключает в себе получение большого количества данных о цели, которые пригодятся в использовании в дальнейшем. В данной статье мы будем рассматривать сбор информации о целевом веб ресурсе, инструменты которые позволяют собрать информацию, некоторые техники. Так вот, как вы наверняка знаете сбор информации делится на 2 этапа. Это активный и пассивный. Во время пассивного сбора наша цель даже не подозревает о действиях которые мы осуществляем(т.е. не знает что мы собираем информацию о ней). Чаще всего этот этап проходит при сборе с сторонних ресурсов(к примеру с google). А при активном сканировании вы уже взаимодействуете с целью(ищите открытые порты).
План сбора информации.
В течении всей статьи будем приддерживатся простенького плана в котором мы из пассивного сбора информации плавно переходим в активный:
- Информация из различных источников(пассивный)
- Основная информация о цели(активный)
- Информация о сети(активный)
Пассивный сбор информации(1)
В этом пункте мы будем пользоваться различными сервисами и гуглом. А именно, будем использовать дорки.
Для тех кто ни разу не имел дела с дорками поясняю. Это специальные параметры поиска вернее сказать что-то вроде дополнительных опций и ограничений вывода при осуществлении запроса. Перейдем к делу.
Когда вы осуществляете запрос в гугл то в ответ видите миллионы различных ресурсов. Допустим я хотел бы научится взламывать wifi и прописал в строке поиска
Код:
Взлом wifi
Вывело 120000 доступных результатов. Но что если мы введем
Код:
Взлом wifi site:codeby.net
Теперь количество результатов снизилось. Оператор site как бы говорит "искать информацию на данном сайте". А что если я хотел бы прочитать какие-либо файлы определенного формата. К примеру .pdf
Код:
Книги filetype:pdf
Вы правильно поняли если предположили что filetype в качестве результата выдает файлы определенного формата. Допустим я хотел бы поискать какие-либо такстовые файлы. Тогда просто объеденим
Код:
site:codeby.net filetype:txt
Как видим мы нашли файл robots.txt
---------------------------------------------------------------------------------------------------------------------------------------------robots.txt - файл ограничивающий доступ к содержимому на сервере для поисковых ботов.
---------------------------------------------------------------------------------------------------------------------------------------------inurl - ищет текст в url'е сайта
intitle - ищет текст в заголовке сайта
Наверное каждый из нас когда-либо искал уязвимые к SQL инъекции ресурсы используя дорки. Так вот давайте найдем сайты с следующим текстом в URL: .php?id=
Код:
inurl:.php?id=
А теперь попробуем найти данные в заголовке
Код:
intitle:"Kali linux"
Уметь искать информацию с использованием дорков очень полезно. Так как на пассивный поиск без использования прочих поисковиков уйдет немало времени.
Активный сбор информации(2)
Наконец мы пришли к очень интересному пункту. Это сбор основной информации о целевом ресурсе. Сюда входят такие данные как:
- информация о доменах
- информация о поддоменах
- контактная информация
- местонахождение
- диапазон IP адресов
- CMS
- 2ip - сервис который даст вам достаточно информации о вашей цели. В числе информации IP, cms, местонахождения и.т.п.
- Echosec - данный сервис показывает все посты созданы в социальных сетях(полезно для поиска сотрудников целевого веб ресурса)
- Atchive - этот сервис сохраняет копии практически всех сайтов.
- NetCraft - сервис дает вам информацию о DNS, выводить диапазон IP адресов, поддомены и др.
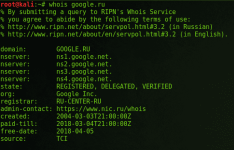
- Ripe.net - сервис дает информацию о диапазоне IP адресов.
Код:
whois site.comНашему взору представляется очень много информации. Если повезет то можно и увидеть email и имя которые были указаны при регистрации DNS. А если мы введем IP вместо доменного имени, то получаем диапазон ip адресов

Для автоматизации сбора информации существует целый фреймворк - recon-ng
Код:
git clone https://github.com/jorik041/recon-ngВообще recon-ng уже входит в состав Kali. Давайте найдем поддомены google.ru(не реклама)
Код:
> load google_site_web
> set source google.com
> run
Используя сервисы описанные выше и инструменты которые присутствуют в статье, можно получить уйму информации. Но также ее нужно отсортировать. Для этого нам понадобится Maltego. Его уже описывали на форуме - здесь.
CMS. Чаще всего cms можно опеределить заглянув в meta тегв коде страницы целевого веб ресурса.
Также определить cms можно сервисом 2ip. Вот пример определения cms одного веб сайта

Активный сбор информации(3)
В этом пункте мы поговорим о получении информации о сети. То есть информацию о
- открытых портах
- dns записях
- активных хостах
- ОС системы
- версии ПО и ОС
Код:
nmap 192.168.1.1Чтобы про сканировать нужный вам порт существует такая опция как -p. Пример использования
Код:
nmap 192.168.1.2 -p 4444Теперь попробуем узнать ОС целевой системы. На этот случай nmap обладает опцией -O
Код:
nmap 192.168.1.2 -OА для определения версий ОС и ПО при этом получить много полезной информации можно использовав данную команду
Код:
nmap SITE.ru -sV -A -v -O
С этим мы определились. Перейдем к активным хостам. У нас имеется полученный ранее диапазон. Воспользуемся fping
Код:
fping -Asg 95.213.8.0/24 -r 3 >> ip.lst
cat ip.lst | grep alive
Как видим живых хостов много. В итоге у меня получился огромный список живых хостов.
DNS. Попробуем получить информацию из mx и ns записей.
Для этого у нас есть nslookup.NS записи - показывают какие DNS обслуживают данную зону.
MX записи - определяют почтовые серверы обслуживающие данную зону.
Для определения ns записей пишем следующее
Код:
nslookup
> set q=ns
> google.com
Код:
nslookup
> q=mx
> google.comВывод.
Недавно на форуме появилась статья от @Ondrik8 в которой описаны некоторые инструменты для сбора информации и пентеста веб ресурсов. Прочитать можно - тут
Так вот, сбор информации является немаловажной частью в пентесте web ресурсов, и даже не именно web ресурсов а вообще систем, сетей и прочего. Всем спасибо! До встречи в следующей части)
Вложения
Последнее редактирование:
