Статья для участия в конкурсе Тестирование Веб-Приложений на проникновение.
Статья является приквелом к циклу, который я хочу запустить: Истории за кодом. В нём я расскажу о вещах, которых как мне кажется не хватает местным «кодерам». Будут разговоры об архитектуре, базах данных, напишем с вами свой sqlmap, разберём пару эксплойтов, напишем сканер по диапазону, автоатакер по диапазонам и прочее. Будет очень весело. От меня код, проект на gitlab, постоянные ревью ваших пул реквестов, обсуждения и открытые таски. В целом – это то, что я хотел сделать для школы codeby, но делаю бесплатно и на добровольных началах. Своего рода интерактивная обучалка-стажировка для всех. Быстрая публикация статьи и не очень близкая по духу мне тема, связана, разумеется, с конкурсом. Итак погнали.
Современная enterprise разработка, нашими усилиями, свелась к использованию и знанию библиотек, однако даже сейчас многие задают просто поражающие вопросы, я много раз пытался поставить себя на место таких «спрашивающих» и пришёл к выводу, что они просто лентяи.
Ну посудите сами, тот самый минимум необходимый для работы с библиотеками, для создания приложений, это формирование, внимание, строк! Не верим? Хорошо, по крайней мере в тематики этичного хакинга это так. А чтоб мозг не скучал рассмотрим дырку с rootme, только дырка для sql-инъекции, а я буду её брутить (про sql-инъекцию напишу в дальнейших статьях цикла.
Теория
Для успешной атаки важно представлять такое понятие, как, сравнение с ожидаемым результатом.
Оно бывает позитивным и негативным. Позитивное тестирование – это тестирование, при котором мы ожидаем увидеть позитивный эффект. В случае с атакой перебором – позитивным эффектом являлось бы надпись “Welcome back, admin” ну или нечто подобное.
Негативное же тестирование – это такое тестирование, при котором мы ожидаем увидеть негативный результат. Например: «no such user/password» ну или нечто подобное.
Так вот, сейчас мы займёмся негативным тестированием – но для начала – задумаемся о вещах, которые мы сейчас знаем:
- Мы знаем, что запрос на аутентификацию отправляется http-методом POST.
- Мы 100% знаем, что в случае неверного сочетания user/password мы получим html страничку в теле которой будет содержаться заголовок, который написан криво: открывается тегом h3 а закрывается тегом h2, с текстом: «Error: no such user/password»
- Мы знаем, что такое негативное и позитивное тестирование.
Читаем строку из словаря -> парсим её разделитель -> приводим к объекту -> отправляем пост запрос на атакуемый сервер -> получаем ответ -> ищем в ответе имеющиеся сообщением о ошибке -> если нашли переходим к следующей строке в словаре и так пока либо не получим отличную ошибку, либо не получим доступ, либо бан ip. Что делать в подобных ситуациях я думаю рассказывать не надо, хотя может как-нибудь потом опишу.
Есть много способов оптимизировать описанный процесс (поделитесь с другими в комментариях) тут же мы рассматриваем базу.
Практика:
Начнём с того, что, любой код, который делает что-то с web’oм содержит в себе как минимум post и\или get запросы. Говоря почти человеческим языком: это дерьмо как-то работает с rest api того дерьма. Ну или что-то в этом духе. Опять же, направляю вас учить мат часть: как работает интернет, что это вообще за rest такой, и почему 80% людей понятия не имеют о чистом rest, и вообще рассуждения о нём выходит за рамки стати.
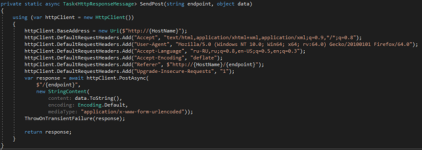
Давайте прикинем базовый классик на C# который будет шаблоном наших дальнейших api клиентов. Начнём с необходимых методов, для решения конкретной таски с
Ссылка скрыта от гостей
. А именно с метода создания пост запроса.
Wow и всё. На вашем любимом питоне это короче выглядит, но суть, как всегда, не в это. Что делается в этом методе… Создаётся HttpClient (ВНЕЗАПНО!) что это такое? Давайте-ка подумаем… кхмм… даже не знаю! Вероятно, это такая штука, которая как-то (ВНЕЗАПНО!) взаимодействует с http? Так, рассуждаем дальше, я только валидол под язык положу… Неужели это такая штука, которая каким-то образом работает с http протоколом? Кхм.. ВЕРОЯТНО!
Ладно, я больше не буду разговаривать с тобой как с дауном, дорогой читатель, прости! Действительно как мы видим дальше наш клиент отправляет асинхронно пост запрос. Почему асинхроно? Пока тебе хватит следующей информации: в случае асинхронной отправки, мы не обязаны ждать пока нам вернётся ответ, мы просто продолжаем работать с приложением дальше, грубо говоря: чтоб интерфейс не подвисал, кхах.. (на самом деле, я просто не хочу рассказывать скучную теорию потоков и процессов, и почему вот это вот всё происходит, но очевидно, что это не значит, что я её не знаю и тем более не значит, что вам её не нужно знать, наоборот, смысл статьи как раз в том, что бы все поняли как важны тривиальные вещи.)
Итак у нас есть метод, отправляющий пост запрос на адрес HostName, по конечной точке endpoint ( это всё что идёт после доменной зоны) Справедливости ради стоит сказать, что content-type тут задан из-за заголовка, так же создан cookie контейнер, который я почему то не привёл в статье, но все эти настройки объекта, можно узнать (внезапно из документации msdn).
Вернёмся к rootme, посмотрим в devtools(F12) вкладку сеть, а именно за тем, что происходит при отправке запроса с введёнными данными. Т.е. нормально выражаясь, проведём анализ запроса. Вводим admin/admin и получаем следующую картину:

Могу вас заверить нас интересует POST запрос, посмотрим на него внимательнее:

Поверите ли вы мне, что это все необходимые нам heder’ы? Осталось узнать о содержании!

Пожалуй ещё вкладка ответ вызывает интерес

Внезапно, правда? Значит, что мы имеем уже сейчас? Какой вектор атаки у нас есть? Правильно – любимый брутфорс. (делать это я разумеется не буду… а хотя ладно буду, но покажу как написать маленький, малюсенький такой брутфорсер ( без приколюх типа прокси, параллелизма и прочего)
Я немного изменил первоначальный метод: добавил headerы. И теперь он выглядит так

Как видите в этом тоже нет ничего сложного, просто получаем данные из анализа запроса и добавляем их в defaultsheader. Разумеется, тут можно подменять useragenta, чтоб не палить браузер, и прочее. По-хорошему бы это всё нужно вынести в настройки, но мне лень объяснять за рефакторинг и чистоту кода и т.д. поэтому делать я этого не буду. Хотя ладно приоткрою немного завесу тайн: по уму бы сделать в базовом классе настроечное свойство, а в методе, в цикле пробежаться и добавить header’ов примерно так:

соответственно в наследнике в конструкторе зададим свойство Headers (а в дальнейшем можем из бд или файла читать, в зависимости от потребностей)

Дальше как говорится дело техники. Ночь. Улица. Словарь. Брутфорс.
Положим x на y, а так же что у нас имелся словарь вида login;pass в txt файле. Спарсим, txt файл (разумеется, надо понимать, что если у нас словарь размером с петабайт, грузить его целиком в оперативную память идея не то, что плохая… феерически идиотская, используйте фрагментированное чтение). В итоге у меня получился вот такой вот классик для сервиса словаря.

Разумеется, как сделать «фрагментированное чтение через take-offset» я опустил, вы и сами разберётесь). Таким образом мы имеем(почти) полностью функциональный инструмент для брутфорс-атаки. Почему почти? Потому что, понятное дело нужно организовать взаимодействие классов.
Ну дело за малым:

Метод брута

Демонстрация:

Что мы имеем? Рабочее приложение, которое решает определённую задачу. С первого взгляда всё классно-шоколадно, но увы спешу вас расстроить – это не так. И тут начинается основная часть статьи. А я пока за кофе схожу.
Давайте я вам со сто процентной вероятностью скажу: что такое решение никуда не годится. Его архитектура не обеспечивает приложению ни масштабируемости, ни тестируемости, кроме того, усложняет дальнейшее сопровождение. Вот так выглядит uml-диаграмма сейчас.

И теперь мы подошли к основной дилемме архитектуры и основной её эвристике: будьте готовы выбросить своё первое решение. Макконнелл описывает архитектуру системы, как грязную проблема. То есть это такая проблема, для которой оптимальное решение, появляется лишь после нескольких релизов. Так, например, при постройке моста, одни архитекторы не учли, силу ветра. В итоге при урагане мост рухнул, но эту проблему невозможно было решить на тот момент. Новый мост удерживает порывы урагана и всё классно. Так и с программным обеспечением, большинство проблем невозможно решить (а о большинстве проблем вы даже не догадаетесь, независимо от опыта разработки) в первом решении.
Давайте начнём анализ нашей диаграммы. На первый взгляд очевидна проблема с наименованиями. Я завязал классы на название сайта. Так делать не стоит, давайте исправим это переименовав их.
Класс RootMeModel содержит два свойства (атрибута класса) Login и Password. Очевидно, что у такой структуры данных есть более подходящие названия, например AuthenticationsData (данные аутентификации). Логично? Максимально. Согласитесь, человеку, который наш код вдруг будет читать словосочетания данные аутентификации скажет куда больше, чем «модель получи root досутп от меня» (перевёл как со сленга).
Так же в данном классе есть неочевидная проблемка – переопределённый метод ToString. Вот его сигнатура и тело.

Данный метод хорошо сработает, в случае, если сервер принимает данные в виде
Код:
"application/x-www-form-urlencoded"И не сработает, если нужно передавать эти данные в json формате или yaml… Думаю проблема ясна, но вот так в лоб её не решить. Поэтому пока что напишем TODOшку

Лирическое отступление для TODOшек. Во многих редакторах кода, то что вы помечаете комментарием TODO отображается на различных таск листах, тем самым давая вам удобную навигацию по коду. Так, например, для Visual Studio Enterprise 2017, которую я использую, Таск лист выглядит так:

Следующее, что стоит сделать – это разделить приложение на уровни для изоляции проблем, в частности. Так если ошибка будет в уровне доступа к базе данных\файловой системы, она будет в одном месте, если же ошибка будет в алгоритме атаке, она будет лежать на другом уровне и так далее. Традиционно предлагается следующее разделение:
- Data access layer – слой доступа к данным.
- Business layer – слой бизнес логики, в нашем контексте тут будут хранится алгоритмы атаки: на данный момент это способы брутфорса, определение полей для sql инъекций, определение количества столбцов в таблице для sql инъекций и так далее. Классы данного слоя часто называют сервисами.
- Presentation/UI layer – слой пользовательского интерфейса. Будь то веб приложение, консольной, телеграмм бот, или апи сервис.
- Frontend layer – для spa веб-приложений часто стоит выделить этот слой, так как порой решения там совсем не тривиальные.
Начнём с Data access layer. Первым делом создадим Class Dynamic library (в дальнейшем dll’ку). Дадим ей название проекта и постфикс DataAccessLayer для удобства. Я называю так: ForAticle.DataAccessLayer. Далее определим структуру папок, следующим образом:

В папке Models у нас будут лежать модели данных для функциональных возможностей нашего приложения. Чаще всего они повторяют структуру базы данных.
В папке Interfaces будут находятся абстракции и интерфейсы. Основная причина существования этой папки, да и вообще подобного тема для целой книги, поэтому поиск основной информации по темам Dependency Injections, Inversion Of Control я оставлю на плечи любознательного пользователя, современный софт без этих понятий не пишется. От себя, конечно же, порекомендую литературу в конце статьи.
В папке DataHandlers будут находится классы доступа к данным. Так же их можно называть репозиториями (и даже в каком то смысле это правильно, хотя момент спорный).
Данные, которые в нашем приложении, можно где-то хранить:
- Словари для перебора
- Словари для подбора названий таблиц для sql
- Header’ы для апи клиентов

Класс ApiClientsSettingsHandler занимается настройкой Апи клиентов, конкретно редактированием, добавлением, удалением Header’ов, HostName’ов и прочего.
Класс BruteForceDictionaryFileHandler занимается хранением словаря в файле. Занимается добавлением новых пар в словарь, их фрагментированном чтением и прочим необходимым.
На момент написания этих слов полная структура выглядит вот так

Диаграмма UML будет иметь следующий вид

Теперь перейдём к слою с бизнесс логикой. Опять же создаём dll’ку называем её похожим образом, т.е. ForAticle.BusinessLayer и задаём общую структуру.

Принцип похож на DataAccessLayer только вместо папки DataHandlers, а так же добавились такие вещи как: BusinessModels, DataTransferObjects, Infrastructure. Всё по порядку:
BusinessModels – папка, которая будет содержать в себе специальные бизнес-объекты, которые, в отличие от DataTransferObjects будут не только хранить в себе состояние, но и выполнять определенные действия.
DataTransferObjects – следовательно нужны для передачи состояния и данных между слоями приложения. Зачастую эти объекты повторяют модели из слоя доступа к данным, но это не всегда так. Такие объекты нужны для того, что бы окончательно инкапсулировать слой доступа к данным и слои бизнес логики, представления.

Infrastructure – папка для инфраструктурных классов. Чаще всего для того, чтоб очистить код от рутинных вещей, таких как, разрешение зависимостей, вводят специальные объекты. Так в нашем случае, я использую DI-контейнер ninject, один из способов разрешения зависимостей требует создания настроечного класса-реализации NinjectModule. Выглядит это так:

Это опять же о «сложной теме, которая на самом деле простая, но надо погуглить». Структура проекта и UML диаграмма:


В следующей статье поговорим про Presentation Layer, а также
- Расскажу про хорошие архитектурные трюки
- Подключим бд
- Начнём писать sqlmap и даже больше – свой легко масштабируемый и расширяемы фреймворк.