Всем доброго времени суток!
В продолжение первой и второй частей сегодня допишем последнее - дешифратор той каши, что у нас получалась на первых этапах.
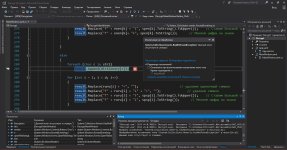
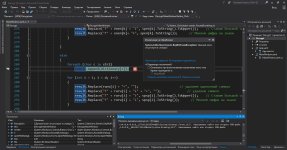
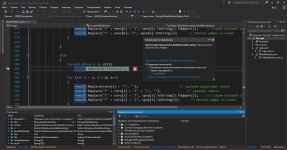
Сначала объявим адресные пространства, как всегда:

Потом напишем подпрограмму, которая будет принимать наш Base64, декодировать его обратно в AES, а из него уже будем получать "неформатированный" вывод.
Функция расшировки обратна функции шифрования из первой части (входной параметр это string cipherText).

Главное, чтобы совпадали параметры salt, initialVector, keySize и hashAlgorithm.
Далее идут такие строки. Обращаем внимание на последнюю: она конвертирует Base64 в байты:

ибо как мы помним у нас Base64+AES шифрование.
Собственно, далее мы вызываем метод AES и CBC-режим (подробнее о CBC

Далее у нас "матрешка" из потоков. Благодаря ей и происходит декодировка. В конце потоки обязательно закрываем, чтобы освободить ресурсы.

И не забудем получить результат:

На этом модуль Decrypter() завершен. После его работы у нас будет очень много каши из символов.
Чтобы привести её к более-менее читаемому виду, будем использовать StreamReader, который будет читать наш файл, брать каждую строку, сразу ее декодировать и выводить на экран.
В отличие от предыдущих частей, тут используется оконный интерфейс (WinForms).
Поэтому на заранее созданную кнопку вешаем обработчик и пишем туда:

Затем начинаем читать файл построчно:

т.о. результат будет уже в декодированном виде помещаться в string, а ее мы будем использовать так:

Почему именно так? Чтобы упростить себе задачу и преобразовать какие-то определенные символы или группу символов в другой:

И так далее, думаю смысл ясен. В коде таких конструкций много.
Потом чтобы не грузить себя оптимизацией, весь вывод просто выводим так:

Alltext это TextBox на форме.
Не забудем закрыть файл:

Теперь мы имеем более осознанный текст, но без учета русской и английской раскладки.
Чтобы выполнить преобразование eng-to-rus, придется немного попотеть.
Я всё планировал реализовать через Regex, но времени/навыка не хватает, поэтому для начала учтём, что пользователь мог очень долго держать одну клавишу нажатой.
Воспользуемся кодом, который будет этот момент мониторить через ф-ю MyFunc(string)

Она будет считать повторяющиеся символы и в скобках выводить их количество. Вызов делаем так:

Потом поделим содержимое string на массив string:

А далее начинается "магия". Создадим шаблон символов, для свободного преобразования:

Обращаем внимание на хвостик: там учтён "пробел"")
Создаем их них массив char:

Посчитаем размер массива:

и с помощью Dictionary сделаем сопоставление символов:

Теперь учтём, что у нас могут быть и английский текст и русский.
Попробуем вывести его на экран. Грубо говоря в программе будет два окна: в первом будет идти исходная каша и в ней будет еще и английский текст.
В нижнем - русский (и возможно остатки от корявого декодирования+Англ., ибо код не оптимизирован). Создаем новый StringBuilder, в цикле ищем совпадение с кодами раскладки (шифратор в первой части пишет коды раскладов при их смене). Если совпадение найдено, то чекаем bool-переменную:

Вверху была Eng, ниже - Rus:

Конечный результат толкаем на экран:

Теперь когда мы это дело запустим, то декодировка выглядеть будет примерно так:


Что за стрелки? Это моменты нажатия и отпускания какой-либо клавиши:
↑в↓сем привет↑1↓ означает "Всем привет!"
В данном случае стрелка вверх это SHIFT. SHIFT+1 = !
Паттерн ↑(26)о↓ означает, что я нажимал/удерживал букву О 26 раз подряд.
А вот такая штука goooood←←←←d означает, что после ввода 4 символа было удалено.
Примерно в таком виде лучше и использовать, т.к. самый грамотный анализатор это ваш мозг.
Я сделал робкую попытку упростить задачу, и выдавать на выходе что-то весьма близкое к оригиналу (но мозг никто не отменял) и добавил пару конструкций для обоих языков:

своего рода regex для бедных
Выглядит это "чудо" теперь так:


Ошибки при таком варианте будут, но читаемость увеличилась.
К слову, я использовал программу без этой фишки. Удалось восстановить на 90% тексты некоторых документов+было украдено найдено много логинов/пассов от разных устройств и сервисов.
Сама реализация конечно не идеальна и далека от совершенства, поэтому желающие/знающие больше могут и должны оптимизировать/заменить/улучшить под себя.
Надеюсь эта статья будет полезна!
На этом всё
И не забываем, что цикл статей имеет образовательную цель.
Использование в противоправных целях нарушет закон.
[doublepost=1495683065,1495682286][/doublepost]Исходник во вложении
В продолжение первой и второй частей сегодня допишем последнее - дешифратор той каши, что у нас получалась на первых этапах.
Сначала объявим адресные пространства, как всегда:
Потом напишем подпрограмму, которая будет принимать наш Base64, декодировать его обратно в AES, а из него уже будем получать "неформатированный" вывод.
Функция расшировки обратна функции шифрования из первой части (входной параметр это string cipherText).
Главное, чтобы совпадали параметры salt, initialVector, keySize и hashAlgorithm.
Далее идут такие строки. Обращаем внимание на последнюю: она конвертирует Base64 в байты:
ибо как мы помним у нас Base64+AES шифрование.
Собственно, далее мы вызываем метод AES и CBC-режим (подробнее о CBC
Ссылка скрыта от гостей
)Далее у нас "матрешка" из потоков. Благодаря ей и происходит декодировка. В конце потоки обязательно закрываем, чтобы освободить ресурсы.
И не забудем получить результат:
На этом модуль Decrypter() завершен. После его работы у нас будет очень много каши из символов.
Чтобы привести её к более-менее читаемому виду, будем использовать StreamReader, который будет читать наш файл, брать каждую строку, сразу ее декодировать и выводить на экран.
В отличие от предыдущих частей, тут используется оконный интерфейс (WinForms).
Поэтому на заранее созданную кнопку вешаем обработчик и пишем туда:
Затем начинаем читать файл построчно:
т.о. результат будет уже в декодированном виде помещаться в string, а ее мы будем использовать так:
Почему именно так? Чтобы упростить себе задачу и преобразовать какие-то определенные символы или группу символов в другой:
И так далее, думаю смысл ясен. В коде таких конструкций много.
Потом чтобы не грузить себя оптимизацией, весь вывод просто выводим так:
Alltext это TextBox на форме.
Не забудем закрыть файл:
Теперь мы имеем более осознанный текст, но без учета русской и английской раскладки.
Чтобы выполнить преобразование eng-to-rus, придется немного попотеть.
Я всё планировал реализовать через Regex, но времени/навыка не хватает, поэтому для начала учтём, что пользователь мог очень долго держать одну клавишу нажатой.
Воспользуемся кодом, который будет этот момент мониторить через ф-ю MyFunc(string)
Она будет считать повторяющиеся символы и в скобках выводить их количество. Вызов делаем так:
Потом поделим содержимое string на массив string:
А далее начинается "магия". Создадим шаблон символов, для свободного преобразования:
Обращаем внимание на хвостик: там учтён "пробел"
Создаем их них массив char:
Посчитаем размер массива:
и с помощью Dictionary сделаем сопоставление символов:
Теперь учтём, что у нас могут быть и английский текст и русский.
Попробуем вывести его на экран. Грубо говоря в программе будет два окна: в первом будет идти исходная каша и в ней будет еще и английский текст.
В нижнем - русский (и возможно остатки от корявого декодирования+Англ., ибо код не оптимизирован). Создаем новый StringBuilder, в цикле ищем совпадение с кодами раскладки (шифратор в первой части пишет коды раскладов при их смене). Если совпадение найдено, то чекаем bool-переменную:
Вверху была Eng, ниже - Rus:
Конечный результат толкаем на экран:
Теперь когда мы это дело запустим, то декодировка выглядеть будет примерно так:
Что за стрелки? Это моменты нажатия и отпускания какой-либо клавиши:
↑в↓сем привет↑1↓ означает "Всем привет!"
В данном случае стрелка вверх это SHIFT. SHIFT+1 = !
Паттерн ↑(26)о↓ означает, что я нажимал/удерживал букву О 26 раз подряд.
А вот такая штука goooood←←←←d означает, что после ввода 4 символа было удалено.
Примерно в таком виде лучше и использовать, т.к. самый грамотный анализатор это ваш мозг.
Я сделал робкую попытку упростить задачу, и выдавать на выходе что-то весьма близкое к оригиналу (но мозг никто не отменял) и добавил пару конструкций для обоих языков:
своего рода regex для бедных
Выглядит это "чудо" теперь так:
Ошибки при таком варианте будут, но читаемость увеличилась.
К слову, я использовал программу без этой фишки. Удалось восстановить на 90% тексты некоторых документов+было
Сама реализация конечно не идеальна и далека от совершенства, поэтому желающие/знающие больше могут и должны оптимизировать/заменить/улучшить под себя.
Надеюсь эта статья будет полезна!
На этом всё
И не забываем, что цикл статей имеет образовательную цель.
Использование в противоправных целях нарушет закон.
[doublepost=1495683065,1495682286][/doublepost]Исходник во вложении