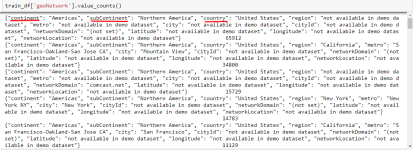
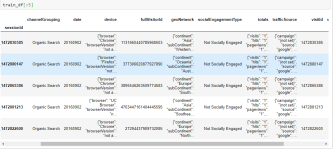
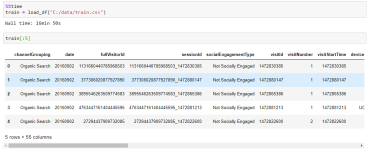
Добрый день,есть csv файл с двенадцатью столбцами,4 из них содержат json объекты(пары ключей и значений),как видно на скриншоте какие то столбцы содержат наблюдения int некоторые str,и некоторые json

нужно привести этот csv файл в датафрейм объект библиотеки pandas,так что бы взамен 4 признаков в формате json построить столбцы ключей,(что бы не путаться представим что их всего 3),которые находятся в этих самых четырех признаках,например вместо столбца geoNetwork,нужно воссоздать 3 новых - сontinent , subContinent, и country, значениях которых будут их ключи,то есть получается что столбец geoNetwork со значениями словарей json формата нужно удалить,а столбцы сontinent , subContinent, и country создать, со значениями которые у них были ранее в json`е.

после поиска в гугле остановился на том что столбцы json формата будут парсится питоном,вся функция :
Python:
#функция принимает csv файл с данными и список столбцов которые нужно преобразить json формата
def load_df(csv_path='C:/data/train.csv', JSON_COLUMNS = ['device', 'geoNetwork', 'totals', 'trafficSource']):
# создается обьект DataFreme
#функция считывает все данные,НО все json cтлб будут парситься питоном - это параметр converters
df = pd.read_csv(csv_path,converters={column: json.loads for column in JSON_COLUMNS},
dtype={'fullVisitorId': 'str'})
#цикл проходит по всем js стлбц и делает разреженным словари в столбц(если в один словарь
#был волжен другой словарь то после преобразования они сливаються в 1,тот который корневой)
for column in JSON_COLUMNS:
column_as_df = json_normalize(df[column])
column_as_df.columns = [f"{column}.{subcolumn}" for subcolumn in column_as_df.columns]
df = df.drop(column, axis=1).merge(column_as_df, right_index=True, left_index=True)
return df
но мне кажется что это неправильный подход,слишком долго и если выборка будет большая,от 1гб ,то такой подход будет невозможен,все дело в том что pandas основывается на библиотеке numpy а та в свою очередь написана на С и Fortan`е, поэтому парсинг пандосом занимает отсносительно немного времени,в отличии от чистого питона, возможно кто то подскажет лучшее решение,без использования циклов,буду рад любым идеям,подсказкам.