Доброго времени суток, codeby.
Первоисточник:
Перевод: Перевод выполнен от команды Codeby
В предыдущей части мы нашли адрес Kernel32.dll, проходя через LDR структуру. В этой части мы сконцентрируемся на нахождении адреса функций (известных как DLL символы) в Kernel32.dll и вызовем их путем предоставления аргументов. Одним из методов вызова этих символов является использование LoadLibraryA с целью нахождения адреса этих символов от Kernel32.dll. Однако, мы этого делать не будем, т.к. это слишком легко. Основная цель моей серии блогов является помочь людям понять, как именно работает код сборки, чтобы было легко писать нулевой шелл-код для любой функции, которая им нужна. В этой части я объясню, как написать шелл-код для GetComputerNameA, и мы пройдемся по нашему исполняемому файлу в дизассемблере x32dbg, чтобы посмотреть имя хоста компьютера, на котором он запущен.
_start:
Итак, все, что у нас есть прямо сейчас, это адрес Kernel32.dll, 74F50000. Нашим следующим шагом будет нахождение адреса GetComputerNameA в Kernel32.dll и его вызов, предоставляя все необходимые параметры. В предыдущем посте я написал код на С, чтобы найти адрес этой функции из Kernel32.dll и мы знаем, что адрес в моей системе - 74F69AC0. Теперь, если мы вычтем адрес нашего kernel32.dll из 74F69AC0, мы получим 19AC0. Дело в том, что если бы я мог просто добавить это значение к адресу нашего kernel32.dll и попытаться запустить его, он запустился бы в моей системе, но, скорее всего, в любой другой системе он не заработает. Ситуация следующая, Microsoft продолжает обновлять kernel32.dll, и из-за этого в DLL могут быть добавлены новые функции/символы. По этой причине адрес нашей функции будет колебаться в зависимости от обновлений kernel32.dll. Поэтому мы не можем просто добавить этот адрес и попытаться заставить его работать. Таким образом, нам нужно будет динамически пройтись по всем символам внутри kernel32.dll, сравнить имя функции GetComputerNameA со всеми другими функциями внутри kernel32.dll в цикле, и когда мы нажимаем на эту строку сравнения, не смотря на адрес, который мы получили для этой строки, он должен быть нашим адресом, который мы можем добавить к адресу нашего kernel32.dll, чтобы получить базовый адрес нашей функции. Звучит просто? Давайте продолжим!
Теперь, чтобы по-настоящему понять структуру Kernel32.dll, давайте запустим

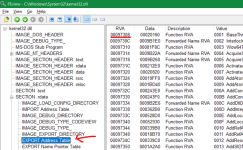
Как только мы открываем kernel32.dll, мы видим внутренние компоненты PE (переносимого исполняемого файла). Если вы кликните по IMAGE_DOS_HEADER с левой стороны, вы увидите то, что называется RVA (Relative Virtual Address), данные с некоторым содержимым в нем и описание с правой стороны.
Теперь, прежде чем мы углубимся в PEview, давайте сначала четко разберемся, что означают эти термины. RVA обозначает Относительный виртуальный адрес (Relative Virtual Address). Этот адрес не зависит от ОЗУ (RAM) и фиксируется до тех пор, пока DLL не будет перекомпилирована или изменена. Внутри Kernel32.dll есть несколько RVA. Например, если скажем, что RVA функции xyz в kernel32.dll равно 200, то базовый адрес функции становится 74F50000 + 200 = 74f50200. Это было просто теоретическое представление о том, как найти базовый адрес. Давайте сначала пройдемся по PEview и объясним, как найти базовый адрес GetComputerNameA. Обычно любой двоичный файл содержит много информации, особенно если это исполняемый файл. DLL и EXE-файлы входят в семейство исполняемых файлов. Теперь, начало любого исполняемого файла всегда содержит тонны информации относительно того, является ли это файлом DOS или файлом ELF, его MZ (Волшебное число (Magic number) для исполняемого файла) или любым другим форматом. Мы можем видеть, что у нас MZ на RVA00000000, что означает, что это исполняемый файл. Точно так же он содержит другую информацию, такую как идентификатор OEM, информация OEM и множество метаданных. Все это нам не интересно. Наша область интересов начинается с RVA0000003C или 0x3C вкратце. Если вы хотите понять, как работает PE Header, вы можете прочитать об этом
На изображении выше показано, что смещение RVA по отношению к новому EXE Header (RVA of Offset to New EXE Header) имеет значение 0x3C и содержит другой адрес, т.е. F8. Теперь, если вы проверите левую часть в IMAGE_NT_HEADER-> Signature, это показывает, что в RVA F8 у нас есть IMAGE_NT_SIGNATURE, и это означает, что это отправная точка нашего PE Header. IMAGE_NT_HEADERS - это, в основном, структура Windows, в случай необходимости дополнительную информацию можно найти
RVA + size of that Table + size of address of the Size of Table = RVA of next Table
Диаграмма только для ознакомительных целей
Замечательно, вот, как мы подсчитываем RVA таблицы. Помните, что каждый адрес всегда будет иметь 4 байта, поэтому нам также нужно это добавить.
Все, что мы добавили - является просто случайными числа, которые были взяты для примера, чтобы вам было проще разобраться. Теперь, если мы углубимся в фактический адрес, вот как это будет происходить. Если вы переходите к PEview в IMAGE_OPTIONAL_HEADER, то первая таблица в IMAGE_DATA_DIRECTORY - это таблица EXPORT, а ее RVA - 170. В ней хранится RVA IMAGE_EXPORT_DIRECTORY, т.е. 972E0.
The IMAGE_EXPORT_DIRECTORY ответственна за хранение всей информации, относящейся к функциям в DLL. Как можно видеть из приведенного выше, изображение содержит три важные вводные:



Прекрасно, позвольте мне объяснить, что означают эти таблицы.

Для легкого понимания я выстроил диаграмму:

ХОРОШО! ЗДОРОВО! Теперь, возможно, вы захотите разобраться с вышеуказанными секторами, прежде чем идти дальше. Это может немного ввести вас в заблуждение, но если вы понимаете концепции должным образом, то сможете справиться с задачей без особых проблем. Теперь давайте приступим к написанию всего, что мы сделали выше в сборке. Сначала мы поместим имя функции в стек, который позже будем использовать для сравнения строк:

Итак, я просто обработал текст в обратном порядке GetComputerNameA, так как значение в стеке переходит от последнего к первому (порядок следования байтов), а затем преобразовал его в шестнадцатеричный формат и разделил его на 8 байтов каждый. Теперь давайте поместим это в стек:
Следующим шагом обычно является прохождение цикла и сравнение строки в стеке со строками в Export Name Pointer Table. Но перед этим давайте рассмотрим пункт «Export Ordinal Table». Если мы снова перейдем к PEview, внутри Export Ordinal Table, мы увидим, что оно начинается с RVA 9A520, а порядковое значение начинается с 0004, т.е. AcquireSRWLockExclusive, и оно продолжает увеличиваться на единицу для каждой функции. Таким образом, если мы опустимся ниже до GetComputerNameA, конечное порядковое значение будет равно 1DF, и оно показывает, что начальное значение равно 1DE (в шестнадцатеричном формате) = 478 в десятичном виде. Поэтому мы можем просто запустить счетчик, который начинается с целого числа 4, и увеличивать его на единицу, пока строка GetComputerNameA не будет сопоставлена в Export Name Pointer Table [ebx-4]. Но здесь есть одна большая проблема. Все было бы хорошо, если и только если бы порядковые величины строились строго в хронологическом порядке. Мы можем видеть в Export Ordinal Table , что порядковое значение начинается с 4, но в Export Address Table оно начинается с 1. Если вы опуститесь ниже в Export Ordinal Table, вы поймете, что первые три значения Export Address Table (BaseThreadInitThunk, InterlockedPushListSList, Wow64Transition) были хаотично вставлены в Export Ordinal Table в случайных местах, и поэтому Export Ordinal Table начинается с 0004.

И, как вы можете видеть, он был случайно вставлен после 47-го значения в Export Name Pointer Table:

Однако, эти места фиксированы по всей ОС. Что нам нужно сделать, это вместо использования отдельного счетчика для порядковой величины применять тот же счетчик, который используется для запуска цикла, и как только мы найдем строку, мы просто исправим счетчик, добавив к нему 1 или 2 целых числа:
Если мы запустим это в x32dbg, то по окончанию цикла это будет выглядеть следующим образом:

Величина EBX, которая использовалась для запуска цикла, составляет 1DC вместо 1DE. Итак, нам нужно будет исправить счетчик, добавив 2, чтобы он стал 1DE, а затем мы можем приступить к извлечению адреса из него:
Итак, если вы производите запуск сейчас, то скорее всего вы должны увидеть название функции в вашем EAX регистре:

К сожалению, адрес моего Kernel32.dll изменился с 74F50000 на 76340000 при сборке этого руководства. Итак, мой последний адрес должен быть 74F5000000 + 19AC0 =74F69AC0, но вместо этого он стал 76340000 + 19AC0 = 76359AC0.
Превосходно! Теперь у нас есть адрес GetComputerNameA, осталось только выделить буфер для параметров этой функции. GetComputerNameA принимает
После выполнения всех упомянутых выше шагов, ваше имя хоста должно быть размещено в виде строки в регистр ESI, который использовался в качестве буфера выше:

Я думаю, эту часть можно на этом закончить. Я предоставил вам всю необходимую информацию по данному этапу. В следующей части я остановлюсь на написании нулевого шеллкода (null free shellcode) и на различных способах минимизации шеллкода.
Первоисточник:
Ссылка скрыта от гостей
Перевод: Перевод выполнен от команды Codeby
В предыдущей части мы нашли адрес Kernel32.dll, проходя через LDR структуру. В этой части мы сконцентрируемся на нахождении адреса функций (известных как DLL символы) в Kernel32.dll и вызовем их путем предоставления аргументов. Одним из методов вызова этих символов является использование LoadLibraryA с целью нахождения адреса этих символов от Kernel32.dll. Однако, мы этого делать не будем, т.к. это слишком легко. Основная цель моей серии блогов является помочь людям понять, как именно работает код сборки, чтобы было легко писать нулевой шелл-код для любой функции, которая им нужна. В этой части я объясню, как написать шелл-код для GetComputerNameA, и мы пройдемся по нашему исполняемому файлу в дизассемблере x32dbg, чтобы посмотреть имя хоста компьютера, на котором он запущен.
_start:
Итак, все, что у нас есть прямо сейчас, это адрес Kernel32.dll, 74F50000. Нашим следующим шагом будет нахождение адреса GetComputerNameA в Kernel32.dll и его вызов, предоставляя все необходимые параметры. В предыдущем посте я написал код на С, чтобы найти адрес этой функции из Kernel32.dll и мы знаем, что адрес в моей системе - 74F69AC0. Теперь, если мы вычтем адрес нашего kernel32.dll из 74F69AC0, мы получим 19AC0. Дело в том, что если бы я мог просто добавить это значение к адресу нашего kernel32.dll и попытаться запустить его, он запустился бы в моей системе, но, скорее всего, в любой другой системе он не заработает. Ситуация следующая, Microsoft продолжает обновлять kernel32.dll, и из-за этого в DLL могут быть добавлены новые функции/символы. По этой причине адрес нашей функции будет колебаться в зависимости от обновлений kernel32.dll. Поэтому мы не можем просто добавить этот адрес и попытаться заставить его работать. Таким образом, нам нужно будет динамически пройтись по всем символам внутри kernel32.dll, сравнить имя функции GetComputerNameA со всеми другими функциями внутри kernel32.dll в цикле, и когда мы нажимаем на эту строку сравнения, не смотря на адрес, который мы получили для этой строки, он должен быть нашим адресом, который мы можем добавить к адресу нашего kernel32.dll, чтобы получить базовый адрес нашей функции. Звучит просто? Давайте продолжим!
Теперь, чтобы по-настоящему понять структуру Kernel32.dll, давайте запустим
Ссылка скрыта от гостей
и просмотрим содержимое DLL. Kernel32.dll находится в C:\Windows\System32, что мы можем увидеть ниже:
Как только мы открываем kernel32.dll, мы видим внутренние компоненты PE (переносимого исполняемого файла). Если вы кликните по IMAGE_DOS_HEADER с левой стороны, вы увидите то, что называется RVA (Relative Virtual Address), данные с некоторым содержимым в нем и описание с правой стороны.
Теперь, прежде чем мы углубимся в PEview, давайте сначала четко разберемся, что означают эти термины. RVA обозначает Относительный виртуальный адрес (Relative Virtual Address). Этот адрес не зависит от ОЗУ (RAM) и фиксируется до тех пор, пока DLL не будет перекомпилирована или изменена. Внутри Kernel32.dll есть несколько RVA. Например, если скажем, что RVA функции xyz в kernel32.dll равно 200, то базовый адрес функции становится 74F50000 + 200 = 74f50200. Это было просто теоретическое представление о том, как найти базовый адрес. Давайте сначала пройдемся по PEview и объясним, как найти базовый адрес GetComputerNameA. Обычно любой двоичный файл содержит много информации, особенно если это исполняемый файл. DLL и EXE-файлы входят в семейство исполняемых файлов. Теперь, начало любого исполняемого файла всегда содержит тонны информации относительно того, является ли это файлом DOS или файлом ELF, его MZ (Волшебное число (Magic number) для исполняемого файла) или любым другим форматом. Мы можем видеть, что у нас MZ на RVA00000000, что означает, что это исполняемый файл. Точно так же он содержит другую информацию, такую как идентификатор OEM, информация OEM и множество метаданных. Все это нам не интересно. Наша область интересов начинается с RVA0000003C или 0x3C вкратце. Если вы хотите понять, как работает PE Header, вы можете прочитать об этом
Ссылка скрыта от гостей
.На изображении выше показано, что смещение RVA по отношению к новому EXE Header (RVA of Offset to New EXE Header) имеет значение 0x3C и содержит другой адрес, т.е. F8. Теперь, если вы проверите левую часть в IMAGE_NT_HEADER-> Signature, это показывает, что в RVA F8 у нас есть IMAGE_NT_SIGNATURE, и это означает, что это отправная точка нашего PE Header. IMAGE_NT_HEADERS - это, в основном, структура Windows, в случай необходимости дополнительную информацию можно найти
Ссылка скрыта от гостей
. Эта структура содержит 3 вещи. MSDN утверждает, что третье в этой структуре - IMAGE_OPTIONAL_HEADER, которая также является
Ссылка скрыта от гостей
. Последний объект в этой структуре - IMAGE_DATA_DIRECTORY, и если вы посещаете
Ссылка скрыта от гостей
для ознакомления с этой структурой, вы увидите, что он содержит виртуальный адрес (RVA) разных таблиц и их размер в структуре. Итак, самый простой способ объяснить это будет выглядеть примерно так.RVA + size of that Table + size of address of the Size of Table = RVA of next Table
| RVA | Размер таблицы | Имя таблицы |
| 1000 | 1500 (size of XYZ struct) | XYZ |
| 2504 (1000 + 1500 + 4) | 2000 (size of ABC struct) | ABC |
| 4508 (2504 + 2000 + 4) | 1900 (size of DEF struct) | DEF |
Замечательно, вот, как мы подсчитываем RVA таблицы. Помните, что каждый адрес всегда будет иметь 4 байта, поэтому нам также нужно это добавить.
Все, что мы добавили - является просто случайными числа, которые были взяты для примера, чтобы вам было проще разобраться. Теперь, если мы углубимся в фактический адрес, вот как это будет происходить. Если вы переходите к PEview в IMAGE_OPTIONAL_HEADER, то первая таблица в IMAGE_DATA_DIRECTORY - это таблица EXPORT, а ее RVA - 170. В ней хранится RVA IMAGE_EXPORT_DIRECTORY, т.е. 972E0.
The IMAGE_EXPORT_DIRECTORY ответственна за хранение всей информации, относящейся к функциям в DLL. Как можно видеть из приведенного выше, изображение содержит три важные вводные:
- RVA 972FC (972E0+0x1C) -> таблица адресов (Address Table) RVA содержит 97308, что является RVA EXPORT Address Table (ниже IMAGE_EXPORT_DIRECTORY)
- RVA 97300 (972E0+0x20)-> Таблица указателей имен (Name Pointer Table) RVA содержит 98C14, что является RVA EXPORT Name Pointer Table (ниже EXPORT Address Table)
- RVA 97304(972E0+0x24)-> таблица адресов RVA содержит 9A520, что является RVA EXPORT Ordinal Table (ниже EXPORT Name Pointer Table)
Прекрасно, позвольте мне объяснить, что означают эти таблицы.
- Таблица экспортных адресов (Export Address Table) содержит RVAs, которые содержат RVA всех символов/функций в kernel32.dll;
- Таблица экспортных указателей имен (Export Name Pointer Table) указывает на названия (строки) символов/функций в kernel32.dll и конечную порядковую величину функции;
- Экспортная порядковая таблица (Export Ordinal Table) содержит нaчальную порядковую величину функции (которая всегда будет на единицу меньше конечной порядковой величины функции).
- Найдите RVA of Offset to Exe Header (0x3C)(смещение RVA по отношению к Exe Header);
- Найдите RVA of Export Table (Таблицы экспорта) [170-F8(Start of PE Header) = 0x78];
- Найдите RVA of IMAGE_EXPORT_DIRECTORY (972E0) в RVA of Export Table;
- Найдите EXPORT Address Table’s RVA (Таблица экспортных адресов) (972E0 + 0x1C = 97308);
- Найдите EXPORT Name Pointer Table’s RVA (972E0 + 0x20 = 97300);
- Найдите (конечную стартовую величину) Ending Ordinal Value of GetComputerNameA in EXPORT Name Pointer Table путем организации циклов и сравнения строк в EXPORT Name Pointer Table (1DF);
- Вычтите 1 от конечной стартовой величины (Ending Ordinal Value), чтобы получить Стартовую порядковую величину (Starting Ordinal Value), ИЛИ организуйте цикл через Порядковую таблицу, чтобы найти Начальную Порядковую величину GetComputerNameA. (мы будем использовать метод вычитания, т.к. это легче выполнять в Asm) (1DF – 1 = 1DE);
- Добавьте EXPORT Address Table’s RVA к (Starting Ordinal Value * Size of Address [4]), чтобы получить RVA of RVA of GetComputerNameA (97308 + 1DE*4 = 97A80);
- Найдите RVA of GetComputerNameA в RVA of RVA of GetComputerNameA (RVA 97A80 contains 19AC0). Добавьте RVA of GetComputerNameA to the Base Address of Kernel32.dll (19AC0 + 74F50000 = 74F69AC0).
Для легкого понимания я выстроил диаграмму:
ХОРОШО! ЗДОРОВО! Теперь, возможно, вы захотите разобраться с вышеуказанными секторами, прежде чем идти дальше. Это может немного ввести вас в заблуждение, но если вы понимаете концепции должным образом, то сможете справиться с задачей без особых проблем. Теперь давайте приступим к написанию всего, что мы сделали выше в сборке. Сначала мы поместим имя функции в стек, который позже будем использовать для сравнения строк:
Итак, я просто обработал текст в обратном порядке GetComputerNameA, так как значение в стеке переходит от последнего к первому (порядок следования байтов), а затем преобразовал его в шестнадцатеричный формат и разделил его на 8 байтов каждый. Теперь давайте поместим это в стек:
Код:
;;;;#push the function name on stack - GetComputerNameA
mov edx, 0x41656d61 ;#ameA in reverse = Aema
push edx ;#Push to stack
push 0x4e726574 ;#terN in reverse = Nret
push 0x75706d6f ;#ompu in reverse = upmo
push 0x43746547 ;#GetC in reverse = CteG
;#Find the address of Export table and store it in ebx
mov edx, [eax + 0x3c] ;#Data at 0x3c is F8 which is moved to edx register: edx = F8
add edx, eax ;#add F8 to the base address of the kernel32.dll to get the RVA till the PE section: edx = 74F500F8
mov edx, [edx + 0x78] ;#add 0x78(170 - F8) to 74F500F8 to get RVA of Image Export Directory: edx = 972E0
add edx, eax ;#add 972E0 to the base address of the kernel32.dll(74F50000) to get the base address of Image Export Directory: edx = 74FE72E0
;#Find the address of the Export Name Pointer table and store it in ecx
mov ecx, [edx + 0x20] ;#add 74FE72E0 and 0x20(97300 - 972E0) to get the RVA of Export Name Pointer Table: ecx = 98C14
add ecx, eax ;#add 98C14 to the base address of kernel32.dll to get the base address of Export Name Pointer Table: ecx = 74FE8C14
mov [ebp-4], ecx ;#Moved the base address of Export Name Pointer Table to [ebp-4] variable on stack: [ebp-4] = 74FE8C14
;#Find the address of the Export Address table and store it in edx
mov edx, [edx + 0x1c] ;#add 74FE72E0 and 0x1c(972FC - 972E0) to get the RVA of Export Address Table: edx = 97308
add edx, eax ;#add 97308 to the base address of kernel32.dll to get the base address of Export Address Table: edx = 74FE7308Следующим шагом обычно является прохождение цикла и сравнение строки в стеке со строками в Export Name Pointer Table. Но перед этим давайте рассмотрим пункт «Export Ordinal Table». Если мы снова перейдем к PEview, внутри Export Ordinal Table, мы увидим, что оно начинается с RVA 9A520, а порядковое значение начинается с 0004, т.е. AcquireSRWLockExclusive, и оно продолжает увеличиваться на единицу для каждой функции. Таким образом, если мы опустимся ниже до GetComputerNameA, конечное порядковое значение будет равно 1DF, и оно показывает, что начальное значение равно 1DE (в шестнадцатеричном формате) = 478 в десятичном виде. Поэтому мы можем просто запустить счетчик, который начинается с целого числа 4, и увеличивать его на единицу, пока строка GetComputerNameA не будет сопоставлена в Export Name Pointer Table [ebx-4]. Но здесь есть одна большая проблема. Все было бы хорошо, если и только если бы порядковые величины строились строго в хронологическом порядке. Мы можем видеть в Export Ordinal Table , что порядковое значение начинается с 4, но в Export Address Table оно начинается с 1. Если вы опуститесь ниже в Export Ordinal Table, вы поймете, что первые три значения Export Address Table (BaseThreadInitThunk, InterlockedPushListSList, Wow64Transition) были хаотично вставлены в Export Ordinal Table в случайных местах, и поэтому Export Ordinal Table начинается с 0004.
И, как вы можете видеть, он был случайно вставлен после 47-го значения в Export Name Pointer Table:
Однако, эти места фиксированы по всей ОС. Что нам нужно сделать, это вместо использования отдельного счетчика для порядковой величины применять тот же счетчик, который используется для запуска цикла, и как только мы найдем строку, мы просто исправим счетчик, добавив к нему 1 или 2 целых числа:
Код:
;;;;;#Find the address of GetComputerNameA in kernel32.dll
findproc:
xor ecx, ecx ;#empty ecx register for string comparison counter
mov esi, esp ;#move GetComputerNameA from stack to esi register
mov edi, [ebp-4] ;#move the base address of Export Name Pointer Table to edi: edi = 74FE8C14
mov edi, [edi + ebx*4] ;#base address of Export Name Pointer Table + Ordinal Value * 4: edi = RVA of the Function's Name(string) in Export Name Pointer Table
add edi, eax ;#add RVA of Name of Function(string) to base address of kernel32.dll to get the Name of the Function in Strings
add cx, 8 ;#move string length of GetComputerNameA to the cx register: len(GetComputerNameA) = 16 bytes = 8 WORD
repe cmpsw ;#compare the number of words in cx register(8) in left to right order from edi register and esi register. Stores the output in ZF Flag
jz findaddr ;#Jump to findaddr label(break loop) if ZF Flag is 1(TRUE), else continue
inc ebx ;#increase the counter to calculate the ordinal value
loop findproc ;#loop findproc label
findaddr:Если мы запустим это в x32dbg, то по окончанию цикла это будет выглядеть следующим образом:
Величина EBX, которая использовалась для запуска цикла, составляет 1DC вместо 1DE. Итак, нам нужно будет исправить счетчик, добавив 2, чтобы он стал 1DE, а затем мы можем приступить к извлечению адреса из него:
Код:
findaddr:
add ebx, 2 ;#patching the EBX counter to change 1DC to 1DE
mov edi, [edx + ebx*4] ;#74FE7308 + 1DE*4: edi = 19AC0
add eax, edi ;#add base address of kerneldll32 to above address to get GetComputerNameA address: eax = 74F69AC0Итак, если вы производите запуск сейчас, то скорее всего вы должны увидеть название функции в вашем EAX регистре:
К сожалению, адрес моего Kernel32.dll изменился с 74F50000 на 76340000 при сборке этого руководства. Итак, мой последний адрес должен быть 74F5000000 + 19AC0 =74F69AC0, но вместо этого он стал 76340000 + 19AC0 = 76359AC0.
Превосходно! Теперь у нас есть адрес GetComputerNameA, осталось только выделить буфер для параметров этой функции. GetComputerNameA принимает
Ссылка скрыта от гостей
:- Указатель на буфер с длиной MAX_COMPUTERNAME_LENGTH + 1 = 15 + 1 = 16 bytes
- Указатель на DWORD, имеющего размер упомянутого выше буфера.
- Итак, все, что нам нужно сделать, это выделить 16 байт в стеке, переместить DWORD в регистр, поместить указатель на этот буфер в стеке, а затем вставить указатель в регистр и после вызвать адрес, который мы сохранили выше в регистре EAX:
Код:
;;;;#Push parameters to stack - GetComputerNameA(LPSTR lpBuffer, LPDWORD nSize)
sub esp, 16 ;#allocate space for LPSTR lpBuffer = MAX_COMPUTERNAME_LENGTH + 1 = 15 + 1 = 16 bytes
mov esi, esp ;#move the stack pointer to lpBuffer in esi
add ecx, 16 ;#since ecx was xor'd above, its empty and we can use it to store the value 16
push ecx ;#push DWORD nSize on stack
push esp ;#push the pointer to nSize (LPDWORD nSize) on stack
push esi ;#push the pointer to lpBuffer on stack
call eax ;#Call the function GetComputerNameAПосле выполнения всех упомянутых выше шагов, ваше имя хоста должно быть размещено в виде строки в регистр ESI, который использовался в качестве буфера выше:
Я думаю, эту часть можно на этом закончить. Я предоставил вам всю необходимую информацию по данному этапу. В следующей части я остановлюсь на написании нулевого шеллкода (null free shellcode) и на различных способах минимизации шеллкода.