На создание данного скрипта меня натолкнула работа с плейлистами m3u, когда я пытался создать чекер работоспособности ссылок. Процесс создания частично описан вот в этой статье. Тогда, для тестирования мне нужно было скачивать большое количество плейлистов. Таковые нашлись в ВК. Вот только скачивать руками все это было достаточно долго. Поэтому, на том этапе, я сделал простенький загрузчик и пользовался им. А позже решил сделать его немного более универсальным, ведь в ВК, к примеру, публикуются не только плейлисты во вложениях, но, также книги и изображения с разными полезными инструкциями. Конечно же, для его создания я использовал Python.

Принцип работы загрузчика довольно прост и использует VK API. Для того, чтобы можно было использовать его в более удобном виде, нашлась для этого библиотека. Таким образом, получаем количество постов в группе, а затем итерируемся по ним в цикле, который учитывает смещение при загрузке постов, так как за один запрос можно получить только 100. Ищем в полученном json вложение, проверяем, есть ли в данном вложении документы того типа, который указан в фильтре. Если да, добавляем в словарь название файла и ссылку для последующей обработки. Считаем количество полученных ссылок. Если их 10, загружаем то, что удалось найти. После чего итерируемся дальше. Конечно же, проверяем, есть ли уже найденные файлы у нас на диске. Чтобы избежать их повторной загрузки. Давайте приступим к созданию загрузчика.
Что потребуется?
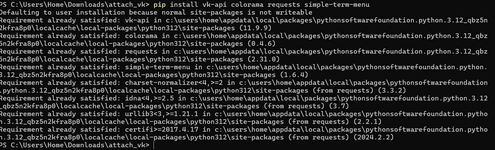
Для работы с VK API потребуется библиотека vk-api. С ее помощью мы будем работать с группой и ее постами. Для установки библиотеки пишем в терминале:
Следующее, что нам понадобиться, это библиотека requests. С ее помощью мы будем загружать найденные вложения. Для ее установки пишем в терминале команду:
В данном скрипте я использовал терминальное меню, работа с которым описана в этой статье. Для его установки пишем команду:
Ну и для раскраски терминального вывода используем библиотеку colorama. Она устанавливается командой:
Также вы можете установить все одной командой:
После того, как нужные библиотеки установлены, заполним блок импорта и импортируем все, что необходимо в скрипт, а также инициализируем colorama.
В данном импорте присутствует импорт set и находящегося в нем токена приложения. Как его получить читайте в данной статье.
После этого, так как мы будем использовать requests, нам нужны заголовки. Определим их в виде глобального словаря.
В данном скрипте основной функционал я попытался реализовать в виде простого класса. Поэтому, перед его написанием создадим пару функций, которые используются вне его.
Запрос ссылки на группу
Возможно, эта функция не стоит отдельного раздела, так как ее размер очень и очень мал. Но, все же она требует упоминания. Создадим функцию main, а также точку входа в скрипт.
Здесь мы запрашиваем у пользователя ссылку на группу и запускаем функцию для создания меню навигации в терминале.
Создание меню навигации
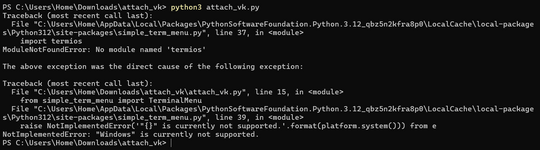
На самом деле, острой необходимости именно в таком меню вовсе нет. Но если возможно сделать, то почему бы и нет? Единственное здесь плохо, теряется кросплатформенность. Однако, если скрипт приглянется пользователям Windows, меню переделать на простое текстовое достаточно просто. А пока, оставим как есть.
Создадим функцию menu(link: str), которая на входе получает ссылку на группу введенную пользователем. Определим несколько списков, один будет пустой, для создания комбинированного списка, а три остальные заполнены. В список ext будут добавляться, при необходимости, если пользователь захочет скачать все типы фалов, расширения из других списков. В списке img хранятся расширения изображений. Если вам нужно что-то более специфическое, его можно дополнить. Список doc хранит расширения документов в разнообразных видах. Также, сюда я добавил архивы, так как бываю вложения с документами запакованными в архив. В списке pls хранятся расширения плейлистов.
На следующем этапе очистим терминал, выведем сообщение для пользователя о выборе формата, создадим список, в котором будут храниться пункты меню. И выведем его на экран, передав в него созданный список.
И дальше обрабатываем выбор пользователя. При нажатии на пункт меню возвращается индекс объекта из списка. Получаем его значение и выполняем действие. Инициализируем класс, который нам еще нужно создать, передадим в него отображаемое имя группы, список с расширениями и запустим код на выполнение фильтрации постов и загрузки вложений.
Также здесь нужно обработать исключения, если пользователь во время выполнения программы нажмет комбинацию клавиш «Ctrl+C». В этом случае мы очищаем терминал, прощаемся с пользователем и выходим из скрипта.
Создание класса загрузчика вложений
Создадим класс для загрузчика. Я назвал его VKAttach. В функции инициализации класса определим, что он должен принимать на входе. Такими параметрами у нас являются: отображаемое имя группы и список с расширениями. Создадим под них соответствующие переменные, чтобы данные параметры были доступны в любой функции класса. Создадим сессию VkApi, в которую передадим токен приложения. Как получить токен можно почитать в этой статье.
Определим переменные, которые будут заполнятся либо в процессе работы функций, либо непосредственно при инициализации. Парсим отображаемое имя группы из переданных в функцию данных (ссылки) — self.group_name. Получаем информацию о группе, а именно ее ID и на всякий случай отображаемое имя - self.group_id, self.screen_name. Получаем количество постов в группе — self.post_count. Определяем переменную в которую поместим ссылку на директорию для загрузки вложений self.path. Определим два множества: self.files и self.files_url. В первом множестве будут храниться полученные имена файлов в директории загрузки, в случае если мы догружаем вложения. В это же множество будем добавлять имена загруженных в процессе работы файлов, чтобы избежать загрузки дубликатов. Во второй переменной будем хранить имя загружаемого файла и ссылку на него. Содержимое данного множества является временным и очищается после каждой загрузки файлов из него.
Парсим отображаемое имя группы
Создадим функцию parse_group_name(self) -> str. В работе она будет использовать только глобальные переменные, а возвращать отображаемое имя группы из строки переданной пользователем.
Здесь все просто. Для начала проверяем, не заканчивается ли ссылка «/». Если да, убираем его. Затем проверяем, на что начинается переданная строка. Если это http — делим полученную строку по слешу, и забираем последний элемент, который и будет отображаемым именем группы. В случае же, когда не найдено ни одного признака, просто передаем полученное значение.
Получаем базовую информацию о группе
Для дальнейшей работы необходимо получить ID группы, а также, на всякий случай, отображаемое имя. И хотя в документации не делается упор на то, чтобы при запросе к группе указывать ее ID, все же, для верности и во избежание ошибок лучше перестраховаться.
Создадим функцию get_group_info(self) -> tuple. На выходе она возвращает кортеж из двух объектов: ID группы и отображаемого имени.
Делаем запрос с помощью метода groups.getById, куда передаем отображаемое имя группы, токен приложения и используемую версию API. Возвращаем полученные параметры. В случае ошибки обрабатываем исключение и выходим из скрипта. Исключение может возникнуть если передано неправильное отображаемое имя группы, либо группа имеет статус закрытой. Ну или по какой другой причине. Так что, лучше обработать.
Получаем количество постов в группе
Создадим функцию get_post_count(self) -> int. С ее помощью мы получим количество постов в группе. Возвращает она целое число, которое и равно количеству постов. Выполняем запрос и забираем из полученного json значение по ключу «count». Запрос выполняем с помощью метода API — wall.get. Для получения данных в него необходимо передать ID группы, которое должно начинаться с «-», чтобы API понимал, что мы делаем запрос не к пользователю, а группе. Токен приложения, смещение, так как при данном запросе мы можем получить максимально 100 значений. Количество получаемых значений в словаре. В данном случае, для того, чтобы получить общее количество постов, нам достаточно получить данные об одном из них. В возвращаемом json в ключе count содержится данное значение. Ну и версию используемого API. Обрабатываем исключение, если это закрытая группа.
Получаем данные о файлах в директории
Для того, чтобы нормально выполнять докачку вложений, нужно получить данные из директории в которую эти вложения скачивались и поместить их названия в множество, с которым мы будем впоследствии сверятся. Создадим функцию scan_dir(self). Параметры для работы она берет глобальные. Потому передавать в нее ничего не нужно. Также она ничего не возвращает, только в процессе работы заполняет глобальное множество полученными значениями.
Проверяем, существует ли директория. Итерируемся по файлам которые в ней содержаться. Забираем имя файла и добавляем в множество.
Функция для загрузки файлов вложений
Создадим функцию get_file(self, url: str, title: str). На вход она получает ссылку для загрузки вложения, и имя вложения, с которым мы его будем сохранять. На входе имя вложения уже имеет расширение, потому особых манипуляций производить с ним не нужно.
Выполняем GET-запрос, в который передаем ссылку на вложение и заголовки. Если статус код в пределах 2ХХ, пытаемся скачать его и сохранить по определенной ранее глобальной директории в байтовом режиме. То есть, записываем на диск загруженный контент. В теории, для уменьшения нагрузки на оперативную память с запрос можно было бы добавить параметр stream со значением True, и затем итерироваться по содержимому загружая его частями и сохраняя на диск. Ну и обрабатываем исключение соединения, если таковое вдруг произойдет.
Функция вывода (печати) информации в терминал
Изначально этой функции в общем-то не предполагалось. Но, так как выводить на экран нужно информацию из разных мест и, во многих местах она просто дублируется, было решено создать отдельную функцию, чтобы не повторятся. Создадим функцию print_info(self). Параметры и переменные для работы она берет глобальные.
Для начала очищаем терминал. Выводим информацию о группе. То есть ее ID и отображаемое имя. Выводим количество постов в группе, количество загруженных файлов в директории для загрузки вложений. Итерируемся по множеству с объектами содержащими название загружаемого файла и его ссылку. Забираем название и выводим в терминал информацию о найденных вложениях.
Получение постов и поиск в них информации о вложениях
Что же, вот мы и добрались до основной функции, в которой и происходит все действие. Давайте ее создадим. Я назвал данную функцию get_posts(self). Она ничего не получает помимо глобальных параметров, ничего не возвращает, а только лишь занимается получением постов и их обработкой.
Для начала запустим таймер, чтобы определить, сколько времени будет длится загрузка вложений. Выведем информацию для пользователя в терминал и просканируем директорию на наличие файлов, если таковые имеются с прошлой работы программы. Ну и вообще, если имеются в директории какие-либо файлы.
Запускаем цикл, в котором будем итерироваться по количеству постов в группе, со смещением 100, так как за один запрос можно получить информацию только о 100 постах. Снова просканируем директорию. И получим информацию о первых 100 постах. Ну или сколько их вообще имеется в группе.
Теперь, когда информация получена, будем итерироваться по каждому посту. Для начала проверяем, есть ли в посте вложения. Если есть, запускаем цикл, который перебирает элементы полученного json. Чтобы забрать все вложения из поста, а их в нем может быть несколько, запускаем цикл по диапазону равному количеству вложений, которое получаем из json. Проверяем значение ключа ext, в котором содержится информация о расширении вложенного файла. Если оно входит в наш фильтр, то есть является изображением, документом или плейлистом, двигаемся дальше. Получаем название файла и тут же его обрабатываем. Дело в том, что ВК обрезает длинные названия и тогда название получается без расширения. Здесь мы устраняем данное недоразумение и добавляем расширение к названию. Ну и, собственно получаем ссылку на файл вложения для последующей его загрузки.
Проверяем, не равна ли длина временного списка с объектами для загрузки 10. Ну или, если вложений несколько, она может стать больше. Хотя, сколько тестировал, такого не происходило ни разу. Но, на всякий пожарный. Выводим информацию пользователю в терминал. Проверяем, существуют ли директории для загрузки файла. Если нет — создаем. Просто печатаем отступ для красоты. Запускаем потоки с помощью ThreadPoolExecutor, определяем максимальное количество потоков равным 10. Больше собственно и не надо. Да и опасно. Кто знает, что там у ВК в коде. Могут и блокнуть за большое количество запросов. Итерируемся по временному множеству с объектами для загрузки. Забираем из них название и ссылку. Добавляем название в множество, с помощью которого проверяем дубликаты загружаемых файлов. И запускаем функцию скачивания в потоках, передавая в нее ссылку для загрузки и название для сохранения. После очищаем временное множество и снова печатаем отступ. Тоже для красоты ))).
Ну и, почти напоследок, проверяем, если ли полученный заголовок в множестве для проверки. Если нет, добавляем в множество для загрузки. Ну, а если есть, сообщаем об этом пользователю. Если тот успеет что-то разглядеть )).
Ну и последняя часть кода этой функции. Дело в том, что количество вложений в постах группы не обязательно должно быть кратно десяти. А потому, по окончании работы цикла у нас может не сработать условие, когда количество объектов в множестве равно или больше десяти. А следовательно, в нем их меньше. Но, так как они все же существуют, их нужно загрузить. Поэтому почти дублируем код из предыдущей части. И догружаем то, что осталось. Ну и выводим в терминал информацию для пользователя о группе, количестве постов, файлов и времени работы скрипта.
Вот, собственно, и все. Скрипт готов. Можно пробовать. Конечно, он получился не супербыстрым, может быть немного быстрее простого перебора без потоков. Но, тем не менее, если вам нужно, для примера, выкачать все вложения из группы библиотеки, вручную это делать нужно будет довольно продолжительное время. А так, можно запустить скрипт, и, если количество постов достаточно большое, пойти, попить чай.
Вот скриншоты работы. Для начала вводим ссылку на группу.

Затем выбираем в меню, какой тип вложений мы хотим скачивать.

Ну и, собственно, сам процесс загрузки, вернее его начало.

Ну, а это еще один скрин, уже из другой группы. На нем видно, что во всех постах группы найдено всего 8 вложений. И все они будут скачаны.

А на это, пожалуй, все.
Спасибо за внимание. Надеюсь, данная информация будет для вас полезна
Ссылка на код скрипта в GitHub
Принцип работы загрузчика довольно прост и использует VK API. Для того, чтобы можно было использовать его в более удобном виде, нашлась для этого библиотека. Таким образом, получаем количество постов в группе, а затем итерируемся по ним в цикле, который учитывает смещение при загрузке постов, так как за один запрос можно получить только 100. Ищем в полученном json вложение, проверяем, есть ли в данном вложении документы того типа, который указан в фильтре. Если да, добавляем в словарь название файла и ссылку для последующей обработки. Считаем количество полученных ссылок. Если их 10, загружаем то, что удалось найти. После чего итерируемся дальше. Конечно же, проверяем, есть ли уже найденные файлы у нас на диске. Чтобы избежать их повторной загрузки. Давайте приступим к созданию загрузчика.
Что потребуется?
Для работы с VK API потребуется библиотека vk-api. С ее помощью мы будем работать с группой и ее постами. Для установки библиотеки пишем в терминале:
pip install vk-apiСледующее, что нам понадобиться, это библиотека requests. С ее помощью мы будем загружать найденные вложения. Для ее установки пишем в терминале команду:
pip install requestsВ данном скрипте я использовал терминальное меню, работа с которым описана в этой статье. Для его установки пишем команду:
pip install simple-term-menuНу и для раскраски терминального вывода используем библиотеку colorama. Она устанавливается командой:
pip install coloramaТакже вы можете установить все одной командой:
pip install vk-api colorama requests simple-term-menuПосле того, как нужные библиотеки установлены, заполним блок импорта и импортируем все, что необходимо в скрипт, а также инициализируем colorama.
Python:
import subprocess
import sys
import time
from concurrent.futures import ThreadPoolExecutor
from pathlib import Path
import requests
from colorama import Fore
from colorama import init
from simple_term_menu import TerminalMenu
from vk_api import VkApi
from vk_api.exceptions import ApiError
from set import token
init()В данном импорте присутствует импорт set и находящегося в нем токена приложения. Как его получить читайте в данной статье.
После этого, так как мы будем использовать requests, нам нужны заголовки. Определим их в виде глобального словаря.
Python:
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 "
"YaBrowser/22.11.3.838 Yowser/2.5 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,"
"application/signed-exchange;v=b3;q=0.9"
}В данном скрипте основной функционал я попытался реализовать в виде простого класса. Поэтому, перед его написанием создадим пару функций, которые используются вне его.
Запрос ссылки на группу
Возможно, эта функция не стоит отдельного раздела, так как ее размер очень и очень мал. Но, все же она требует упоминания. Создадим функцию main, а также точку входа в скрипт.
Python:
def main():
"""
Запрос у пользователя ссылки на группу.
Запуск создания меню выбора дальнейших действий.
"""
link = input(Fore.RESET + "\nВведите ссылку на группу: ")
menu(link)
if __name__ == "__main__":
main()Здесь мы запрашиваем у пользователя ссылку на группу и запускаем функцию для создания меню навигации в терминале.
Создание меню навигации
На самом деле, острой необходимости именно в таком меню вовсе нет. Но если возможно сделать, то почему бы и нет? Единственное здесь плохо, теряется кросплатформенность. Однако, если скрипт приглянется пользователям Windows, меню переделать на простое текстовое достаточно просто. А пока, оставим как есть.
Создадим функцию menu(link: str), которая на входе получает ссылку на группу введенную пользователем. Определим несколько списков, один будет пустой, для создания комбинированного списка, а три остальные заполнены. В список ext будут добавляться, при необходимости, если пользователь захочет скачать все типы фалов, расширения из других списков. В списке img хранятся расширения изображений. Если вам нужно что-то более специфическое, его можно дополнить. Список doc хранит расширения документов в разнообразных видах. Также, сюда я добавил архивы, так как бываю вложения с документами запакованными в архив. В списке pls хранятся расширения плейлистов.
Python:
ext = []
img = ["psd", "jpg", "jpeg", "png", "gif", "tiff", "ico", "svg", "webp", "bmp"]
doc = ["pdf", "odt", "ods", "doc", "docx", "xls", "xlsx", "fb2", "mobi", "epub", "djvu", "djv", "zip", "rar",
"tar"]
pls = ["m3u", "m3u8"]На следующем этапе очистим терминал, выведем сообщение для пользователя о выборе формата, создадим список, в котором будут храниться пункты меню. И выведем его на экран, передав в него созданный список.
Python:
subprocess.call("clear", shell=True)
print(f'{Fore.GREEN}Выбор формата вложений для загрузки\n{"-" * 25}\n')
opt = ["1.Изображения", "2.Документы", "3.Плейлисты", "4.Все форматы", "5.Выход"]
ch = TerminalMenu(opt).show()И дальше обрабатываем выбор пользователя. При нажатии на пункт меню возвращается индекс объекта из списка. Получаем его значение и выполняем действие. Инициализируем класс, который нам еще нужно создать, передадим в него отображаемое имя группы, список с расширениями и запустим код на выполнение фильтрации постов и загрузки вложений.
Python:
if opt[ch] == "1.Изображения":
attach = VKAttach(link, img)
attach.get_posts()Также здесь нужно обработать исключения, если пользователь во время выполнения программы нажмет комбинацию клавиш «Ctrl+C». В этом случае мы очищаем терминал, прощаемся с пользователем и выходим из скрипта.
Python:
def menu(link: str):
"""
Создание меню для навигации с помощью клавиш. Создание экземпляра класса
в соответствии с выбранными параметрами. Запуск получения постов группы и
скачивания вложений, если таковые имеются.
:param link: Ссылка на группу или экранное имя.
"""
try:
ext = []
img = ["psd", "jpg", "jpeg", "png", "gif", "tiff", "ico", "svg", "webp", "bmp"]
doc = ["pdf", "odt", "ods", "doc", "docx", "xls", "xlsx", "fb2", "mobi", "epub", "djvu", "djv", "zip", "rar",
"tar"]
pls = ["m3u", "m3u8"]
subprocess.call("clear", shell=True)
print(f'{Fore.GREEN}Выбор формата вложений для загрузки\n{"-" * 25}\n')
opt = ["1.Изображения", "2.Документы", "3.Плейлисты", "4.Все форматы", "5.Выход"]
ch = TerminalMenu(opt).show()
if opt[ch] == "1.Изображения":
attach = VKAttach(link, img)
attach.get_posts()
elif opt[ch] == "2.Документы":
attach = VKAttach(link, doc)
attach.get_posts()
elif opt[ch] == "3.Плейлисты":
attach = VKAttach(link, pls)
attach.get_posts()
elif opt[ch] == "4.Все форматы":
ext.extend(img)
ext.extend(doc)
ext.extend(pls)
attach = VKAttach(link, ext)
attach.get_posts()
elif opt[ch] == "5.Выход":
raise KeyboardInterrupt
except (KeyboardInterrupt, TypeError):
subprocess.call("clear", shell=True)
print(f"\n{Fore.GREEN}Good By!\n")
sys.exit(0)Создание класса загрузчика вложений
Создадим класс для загрузчика. Я назвал его VKAttach. В функции инициализации класса определим, что он должен принимать на входе. Такими параметрами у нас являются: отображаемое имя группы и список с расширениями. Создадим под них соответствующие переменные, чтобы данные параметры были доступны в любой функции класса. Создадим сессию VkApi, в которую передадим токен приложения. Как получить токен можно почитать в этой статье.
Определим переменные, которые будут заполнятся либо в процессе работы функций, либо непосредственно при инициализации. Парсим отображаемое имя группы из переданных в функцию данных (ссылки) — self.group_name. Получаем информацию о группе, а именно ее ID и на всякий случай отображаемое имя - self.group_id, self.screen_name. Получаем количество постов в группе — self.post_count. Определяем переменную в которую поместим ссылку на директорию для загрузки вложений self.path. Определим два множества: self.files и self.files_url. В первом множестве будут храниться полученные имена файлов в директории загрузки, в случае если мы догружаем вложения. В это же множество будем добавлять имена загруженных в процессе работы файлов, чтобы избежать загрузки дубликатов. Во второй переменной будем хранить имя загружаемого файла и ссылку на него. Содержимое данного множества является временным и очищается после каждой загрузки файлов из него.
Python:
class VKAttach:
"""
Класс для поиска и скачивания вложений из групп ВК.
"""
def __init__(self, group_url: str, ext: list):
"""
Инициализация класса.
:param group_url: Ссылка на группу или экранное имя.
:param ext: Список с расширениями для фильтрации вложений.
"""
self.session = VkApi(token=token)
self.group_url = group_url
self.ext = ext
self.group_name = self.parse_group_name()
self.group_id, self.screen_name = self.get_group_info()
self.post_count = self.get_post_count()
self.path = Path.cwd() / 'channels' / self.screen_name
self.files = set()
self.files_url = set()Парсим отображаемое имя группы
Создадим функцию parse_group_name(self) -> str. В работе она будет использовать только глобальные переменные, а возвращать отображаемое имя группы из строки переданной пользователем.
Здесь все просто. Для начала проверяем, не заканчивается ли ссылка «/». Если да, убираем его. Затем проверяем, на что начинается переданная строка. Если это http — делим полученную строку по слешу, и забираем последний элемент, который и будет отображаемым именем группы. В случае же, когда не найдено ни одного признака, просто передаем полученное значение.
Python:
def parse_group_name(self) -> str:
"""
Парсит имя группы из ссылки. Если указано имя группы без ссылки,
забирает его.
:return: Возвращает имя группы.
"""
if self.group_url.endswith("/"):
self.group_name = self.group_url[0:-1]
if self.group_url.startswith("http"):
self.group_name = self.group_url.split("/")[-1]
else:
self.group_name = self.group_url
return self.group_nameПолучаем базовую информацию о группе
Для дальнейшей работы необходимо получить ID группы, а также, на всякий случай, отображаемое имя. И хотя в документации не делается упор на то, чтобы при запросе к группе указывать ее ID, все же, для верности и во избежание ошибок лучше перестраховаться.
Создадим функцию get_group_info(self) -> tuple. На выходе она возвращает кортеж из двух объектов: ID группы и отображаемого имени.
Делаем запрос с помощью метода groups.getById, куда передаем отображаемое имя группы, токен приложения и используемую версию API. Возвращаем полученные параметры. В случае ошибки обрабатываем исключение и выходим из скрипта. Исключение может возникнуть если передано неправильное отображаемое имя группы, либо группа имеет статус закрытой. Ну или по какой другой причине. Так что, лучше обработать.
Python:
def get_group_info(self) -> tuple:
"""
Получение базовой информации о группе, требующейся для работы скрипта.
Забирается ID группы, а также экранное имя, то имя, что отображается в ссылке.
:return: Возвращает ID группы и экранное имя.
"""
try:
group = self.session.get_api().groups.getById(group_id=self.group_name, access_token=token, v=5.131)
return group[0]['id'], group[0]['screen_name']
except ApiError:
print('Некорректное имя группы')
exit(0)Получаем количество постов в группе
Создадим функцию get_post_count(self) -> int. С ее помощью мы получим количество постов в группе. Возвращает она целое число, которое и равно количеству постов. Выполняем запрос и забираем из полученного json значение по ключу «count». Запрос выполняем с помощью метода API — wall.get. Для получения данных в него необходимо передать ID группы, которое должно начинаться с «-», чтобы API понимал, что мы делаем запрос не к пользователю, а группе. Токен приложения, смещение, так как при данном запросе мы можем получить максимально 100 значений. Количество получаемых значений в словаре. В данном случае, для того, чтобы получить общее количество постов, нам достаточно получить данные об одном из них. В возвращаемом json в ключе count содержится данное значение. Ну и версию используемого API. Обрабатываем исключение, если это закрытая группа.
Python:
def get_post_count(self) -> int:
"""
Получает количество постов в группе.
:return: Возвращает количество постов.
"""
try:
return self.session.get_api().wall.get(owner_id=f'-{self.group_id}',
access_token=token, v=5.131, offset=0, count=1)['count']
except ApiError:
print("Доступ запрещен. Закрытая группа")
sys.exit(0)Получаем данные о файлах в директории
Для того, чтобы нормально выполнять докачку вложений, нужно получить данные из директории в которую эти вложения скачивались и поместить их названия в множество, с которым мы будем впоследствии сверятся. Создадим функцию scan_dir(self). Параметры для работы она берет глобальные. Потому передавать в нее ничего не нужно. Также она ничего не возвращает, только в процессе работы заполняет глобальное множество полученными значениями.
Проверяем, существует ли директория. Итерируемся по файлам которые в ней содержаться. Забираем имя файла и добавляем в множество.
Python:
def scan_dir(self):
"""
Получает файлы из директории, куда скачиваются вложения.
Заполняет глобальный словарь определенный при инициализации класса.
"""
if self.path.exists():
for file in self.path.iterdir():
self.files.add(Path(file).name)Функция для загрузки файлов вложений
Создадим функцию get_file(self, url: str, title: str). На вход она получает ссылку для загрузки вложения, и имя вложения, с которым мы его будем сохранять. На входе имя вложения уже имеет расширение, потому особых манипуляций производить с ним не нужно.
Выполняем GET-запрос, в который передаем ссылку на вложение и заголовки. Если статус код в пределах 2ХХ, пытаемся скачать его и сохранить по определенной ранее глобальной директории в байтовом режиме. То есть, записываем на диск загруженный контент. В теории, для уменьшения нагрузки на оперативную память с запрос можно было бы добавить параметр stream со значением True, и затем итерироваться по содержимому загружая его частями и сохраняя на диск. Ну и обрабатываем исключение соединения, если таковое вдруг произойдет.
Python:
def get_file(self, url: str, title: str):
"""
Скачивает файлы из вложений.
:param url: Ссылка на файл из вложения.
:param title: Название файла.
:return: Возвращает None в случае исключения.
"""
try:
res = requests.get(url=url, headers=headers)
if 200 <= res.status_code <= 299:
with open(self.path / title, 'wb') as f:
f.write(res.content)
print(f'Загрузка: {title}')
except requests.exceptions.ConnectionError:
returnФункция вывода (печати) информации в терминал
Изначально этой функции в общем-то не предполагалось. Но, так как выводить на экран нужно информацию из разных мест и, во многих местах она просто дублируется, было решено создать отдельную функцию, чтобы не повторятся. Создадим функцию print_info(self). Параметры и переменные для работы она берет глобальные.
Для начала очищаем терминал. Выводим информацию о группе. То есть ее ID и отображаемое имя. Выводим количество постов в группе, количество загруженных файлов в директории для загрузки вложений. Итерируемся по множеству с объектами содержащими название загружаемого файла и его ссылку. Забираем название и выводим в терминал информацию о найденных вложениях.
Python:
def print_info(self):
"""
Вывод информации в терминал о группе, количестве публикаций, а также
количестве файлов в директории куда загружаются вложения.
"""
subprocess.call("clear", shell=True)
print(f'\n{Fore.CYAN}Информация о группе\n{"-" * 25}')
print(f'{Fore.GREEN}ID: {Fore.RESET}-{self.group_id} | {Fore.GREEN}Screen Name: '
f'{Fore.RESET}{self.screen_name}')
print(f"{Fore.YELLOW}Количество публикаций: {Fore.RESET}{self.post_count}")
print(f'{Fore.GREEN}Файлы в директории: {Fore.RESET}{len(self.files)}\n')
if self.files_url:
for num, uri in enumerate(self.files_url):
ur = uri.split("\n")[0]
print(f'{str(num+1).ljust(3)}| Найдено: {ur}')Получение постов и поиск в них информации о вложениях
Что же, вот мы и добрались до основной функции, в которой и происходит все действие. Давайте ее создадим. Я назвал данную функцию get_posts(self). Она ничего не получает помимо глобальных параметров, ничего не возвращает, а только лишь занимается получением постов и их обработкой.
Для начала запустим таймер, чтобы определить, сколько времени будет длится загрузка вложений. Выведем информацию для пользователя в терминал и просканируем директорию на наличие файлов, если таковые имеются с прошлой работы программы. Ну и вообще, если имеются в директории какие-либо файлы.
Python:
time_start = time.monotonic()
self.scan_dir()
self.print_info()Запускаем цикл, в котором будем итерироваться по количеству постов в группе, со смещением 100, так как за один запрос можно получить информацию только о 100 постах. Снова просканируем директорию. И получим информацию о первых 100 постах. Ну или сколько их вообще имеется в группе.
Python:
for offset in range(0, self.post_count, 100):
self.scan_dir()
posts = self.session.get_api().wall.get(owner_id=f'-{self.group_id}', access_token=token,
v=5.131, offset=offset, count=100)Теперь, когда информация получена, будем итерироваться по каждому посту. Для начала проверяем, есть ли в посте вложения. Если есть, запускаем цикл, который перебирает элементы полученного json. Чтобы забрать все вложения из поста, а их в нем может быть несколько, запускаем цикл по диапазону равному количеству вложений, которое получаем из json. Проверяем значение ключа ext, в котором содержится информация о расширении вложенного файла. Если оно входит в наш фильтр, то есть является изображением, документом или плейлистом, двигаемся дальше. Получаем название файла и тут же его обрабатываем. Дело в том, что ВК обрезает длинные названия и тогда название получается без расширения. Здесь мы устраняем данное недоразумение и добавляем расширение к названию. Ну и, собственно получаем ссылку на файл вложения для последующей его загрузки.
Python:
if post.get('attachments') is not None:
for i in range(0, len(post.get('attachments'))):
try:
if post.get('attachments')[i].get('doc').get('ext') in self.ext:
title = post.get('attachments')[i].get('doc').get('title')
ex = post.get('attachments')[i].get('doc').get('ext')
try:
title = f'{Path(title).name.split(Path(title).suffix)[0].strip()}.{ex}'
except ValueError:
title = f'{title.strip()}.{ex}'
url = post.get('attachments')[i].get('doc').get('url')Проверяем, не равна ли длина временного списка с объектами для загрузки 10. Ну или, если вложений несколько, она может стать больше. Хотя, сколько тестировал, такого не происходило ни разу. Но, на всякий пожарный. Выводим информацию пользователю в терминал. Проверяем, существуют ли директории для загрузки файла. Если нет — создаем. Просто печатаем отступ для красоты. Запускаем потоки с помощью ThreadPoolExecutor, определяем максимальное количество потоков равным 10. Больше собственно и не надо. Да и опасно. Кто знает, что там у ВК в коде. Могут и блокнуть за большое количество запросов. Итерируемся по временному множеству с объектами для загрузки. Забираем из них название и ссылку. Добавляем название в множество, с помощью которого проверяем дубликаты загружаемых файлов. И запускаем функцию скачивания в потоках, передавая в нее ссылку для загрузки и название для сохранения. После очищаем временное множество и снова печатаем отступ. Тоже для красоты ))).
Python:
if len(self.files_url) >= 10:
self.print_info()
self.path.parent.mkdir(exist_ok=True)
self.path.mkdir(exist_ok=True)
print("")
with ThreadPoolExecutor(max_workers=10) as executor:
for file in self.files_url:
tt = file.split("\n")[0].strip()
url = file.split("\n")[1].strip()
self.files.add(tt)
executor.submit(self.get_file, url=url, title=tt)
self.files_url.clear()
print("")Ну и, почти напоследок, проверяем, если ли полученный заголовок в множестве для проверки. Если нет, добавляем в множество для загрузки. Ну, а если есть, сообщаем об этом пользователю. Если тот успеет что-то разглядеть )).
Python:
if title not in self.files:
self.files_url.add(f'{title}\n{url}')
else:
print(f'{Fore.YELLOW}Существует: {Fore.RESET}"{title}"')Ну и последняя часть кода этой функции. Дело в том, что количество вложений в постах группы не обязательно должно быть кратно десяти. А потому, по окончании работы цикла у нас может не сработать условие, когда количество объектов в множестве равно или больше десяти. А следовательно, в нем их меньше. Но, так как они все же существуют, их нужно загрузить. Поэтому почти дублируем код из предыдущей части. И догружаем то, что осталось. Ну и выводим в терминал информацию для пользователя о группе, количестве постов, файлов и времени работы скрипта.
Python:
if len(self.files_url) < 10:
self.print_info()
self.path.parent.mkdir(exist_ok=True)
self.path.mkdir(exist_ok=True)
print("")
with ThreadPoolExecutor(max_workers=10) as executor:
for file in self.files_url:
tt = file.split("\n")[0].strip()
url = file.split("\n")[1].strip()
self.files.add(tt)
executor.submit(self.get_file, url=url, title=tt)
self.files_url.clear()
self.print_info()
print(f'{Fore.GREEN}Затрачено времени {Fore.RESET}| '
f'{(int(time.monotonic() - time_start) // 3600) % 24:d} ч. '
f'{(int(time.monotonic() - time_start) // 60) % 60:02d} м. '
f'{int(time.monotonic() - time_start) % 60:02d} с.\n')
Python:
def get_posts(self):
"""
Получение всех постов группы, итерация по постам, получение информации о вложениях.
Заполнение словаря в случае найденного вложения, в соответсвии с расширениями
из глобального словаря. Выполняет подсчет объектов в словаре, куда складываются найденные
названия файлов и ссылки. В случае, если количество объектов больше или равно 10,
запускает скачивание файлов вложений.
:return: Возвращает None в случае исключения.
"""
time_start = time.monotonic()
self.scan_dir()
self.print_info()
for offset in range(0, self.post_count, 100):
self.scan_dir()
posts = self.session.get_api().wall.get(owner_id=f'-{self.group_id}', access_token=token,
v=5.131, offset=offset, count=100)
for post in posts['items']:
try:
if post.get('attachments') is not None:
for i in range(0, len(post.get('attachments'))):
try:
if post.get('attachments')[i].get('doc').get('ext') in self.ext:
title = post.get('attachments')[i].get('doc').get('title')
ex = post.get('attachments')[i].get('doc').get('ext')
try:
title = f'{Path(title).name.split(Path(title).suffix)[0].strip()}.{ex}'
except ValueError:
title = f'{title.strip()}.{ex}'
url = post.get('attachments')[i].get('doc').get('url')
if len(self.files_url) >= 10:
self.print_info()
self.path.parent.mkdir(exist_ok=True)
self.path.mkdir(exist_ok=True)
print("")
with ThreadPoolExecutor(max_workers=10) as executor:
for file in self.files_url:
tt = file.split("\n")[0].strip()
url = file.split("\n")[1].strip()
self.files.add(tt)
executor.submit(self.get_file, url=url, title=tt)
self.files_url.clear()
print("")
if title not in self.files:
self.files_url.add(f'{title}\n{url}')
else:
print(f'{Fore.YELLOW}Существует: {Fore.RESET}"{title}"')
except AttributeError:
continue
continue
except IndexError:
return
if len(self.files_url) < 10:
self.print_info()
self.path.parent.mkdir(exist_ok=True)
self.path.mkdir(exist_ok=True)
print("")
with ThreadPoolExecutor(max_workers=10) as executor:
for file in self.files_url:
tt = file.split("\n")[0].strip()
url = file.split("\n")[1].strip()
self.files.add(tt)
executor.submit(self.get_file, url=url, title=tt)
self.files_url.clear()
self.print_info()
print(f'{Fore.GREEN}Затрачено времени {Fore.RESET}| '
f'{(int(time.monotonic() - time_start) // 3600) % 24:d} ч. '
f'{(int(time.monotonic() - time_start) // 60) % 60:02d} м. '
f'{int(time.monotonic() - time_start) % 60:02d} с.\n')Вот, собственно, и все. Скрипт готов. Можно пробовать. Конечно, он получился не супербыстрым, может быть немного быстрее простого перебора без потоков. Но, тем не менее, если вам нужно, для примера, выкачать все вложения из группы библиотеки, вручную это делать нужно будет довольно продолжительное время. А так, можно запустить скрипт, и, если количество постов достаточно большое, пойти, попить чай.
Python:
"""
Скрипт для скачивания вложений из групп ВК. Для работы требует установки
следующих библиотек: pip install vk-api colorama requests simple-term-menu
"""
import subprocess
import sys
import time
from concurrent.futures import ThreadPoolExecutor
from pathlib import Path
import requests
from colorama import Fore
from colorama import init
from simple_term_menu import TerminalMenu
from vk_api import VkApi
from vk_api.exceptions import ApiError
from set import token
init()
headers = {
"user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 "
"YaBrowser/22.11.3.838 Yowser/2.5 Safari/537.36",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,"
"application/signed-exchange;v=b3;q=0.9"
}
class VKAttach:
"""
Класс для поиска и скачивания вложений из групп ВК.
"""
def __init__(self, group_url: str, ext: list):
"""
Инициализация класса.
:param group_url: Ссылка на группу или экранное имя.
:param ext: Список с расширениями для фильтрации вложений.
"""
self.session = VkApi(token=token)
self.group_url = group_url
self.ext = ext
self.group_name = self.parse_group_name()
self.group_id, self.screen_name = self.get_group_info()
self.post_count = self.get_post_count()
self.path = Path.cwd() / 'channels' / self.screen_name
self.files = set()
self.files_url = set()
def parse_group_name(self) -> str:
"""
Парсит имя группы из ссылки. Если указано имя группы без ссылки,
забирает его.
:return: Возвращает имя группы.
"""
if self.group_url.endswith("/"):
self.group_name = self.group_url[0:-1]
if self.group_url.startswith("http"):
self.group_name = self.group_url.split("/")[-1]
else:
self.group_name = self.group_url
return self.group_name
def get_group_info(self) -> tuple:
"""
Получение базовой информации о группе, требующейся для работы скрипта.
Забирается ID группы, а также экранное имя, то имя, что отображается в ссылке.
:return: Возвращает ID группы и экранное имя.
"""
try:
group = self.session.get_api().groups.getById(group_id=self.group_name, access_token=token, v=5.131)
return group[0]['id'], group[0]['screen_name']
except ApiError:
print('Некорректное имя группы')
exit(0)
def get_post_count(self) -> int:
"""
Получает количество постов в группе.
:return: Возвращает количество постов.
"""
try:
return self.session.get_api().wall.get(owner_id=f'-{self.group_id}',
access_token=token, v=5.131, offset=0, count=1)['count']
except ApiError:
print("Доступ запрещен. Закрытая группа")
sys.exit(0)
def scan_dir(self):
"""
Получает файлы из директории, куда скачиваются вложения.
Заполняет глобальный словарь определенный при инициализации класса.
"""
if self.path.exists():
for file in self.path.iterdir():
self.files.add(Path(file).name)
def get_file(self, url: str, title: str):
"""
Скачивает файлы из вложений.
:param url: Ссылка на файл из вложения.
:param title: Название файла.
:return: Возвращает None в случае исключения.
"""
try:
res = requests.get(url=url, headers=headers)
if 200 <= res.status_code <= 299:
with open(self.path / title, 'wb') as f:
f.write(res.content)
print(f'Загрузка: {title}')
except requests.exceptions.ConnectionError:
return
def print_info(self):
"""
Вывод информации в терминал о группе, количестве публикаций, а также
количестве файлов в директории куда загружаются вложения.
"""
subprocess.call("clear", shell=True)
print(f'\n{Fore.CYAN}Информация о группе\n{"-" * 25}')
print(f'{Fore.GREEN}ID: {Fore.RESET}-{self.group_id} | {Fore.GREEN}Screen Name: '
f'{Fore.RESET}{self.screen_name}')
print(f"{Fore.YELLOW}Количество публикаций: {Fore.RESET}{self.post_count}")
print(f'{Fore.GREEN}Файлы в директории: {Fore.RESET}{len(self.files)}\n')
if self.files_url:
for num, uri in enumerate(self.files_url):
ur = uri.split("\n")[0]
print(f'{str(num+1).ljust(3)}| Найдено: {ur}')
def get_posts(self):
"""
Получение всех постов группы, итерация по постам, получение информации о вложениях.
Заполнение словаря в случае найденного вложения, в соответсвии с расширениями
из глобального словаря. Выполняет подсчет объектов в словаре, куда складываются найденные
названия файлов и ссылки. В случае, если количество объектов больше или равно 10,
запускает скачивание файлов вложений.
:return: Возвращает None в случае исключения.
"""
time_start = time.monotonic()
self.scan_dir()
self.print_info()
for offset in range(0, self.post_count, 100):
self.scan_dir()
posts = self.session.get_api().wall.get(owner_id=f'-{self.group_id}', access_token=token,
v=5.131, offset=offset, count=100)
for post in posts['items']:
try:
if post.get('attachments') is not None:
for i in range(0, len(post.get('attachments'))):
try:
if post.get('attachments')[i].get('doc').get('ext') in self.ext:
title = post.get('attachments')[i].get('doc').get('title')
ex = post.get('attachments')[i].get('doc').get('ext')
try:
title = f'{Path(title).name.split(Path(title).suffix)[0].strip()}.{ex}'
except ValueError:
title = f'{title.strip()}.{ex}'
url = post.get('attachments')[i].get('doc').get('url')
if len(self.files_url) >= 10:
self.print_info()
self.path.parent.mkdir(exist_ok=True)
self.path.mkdir(exist_ok=True)
print("")
with ThreadPoolExecutor(max_workers=10) as executor:
for file in self.files_url:
tt = file.split("\n")[0].strip()
url = file.split("\n")[1].strip()
self.files.add(tt)
executor.submit(self.get_file, url=url, title=tt)
self.files_url.clear()
print("")
if title not in self.files:
self.files_url.add(f'{title}\n{url}')
else:
print(f'{Fore.YELLOW}Существует: {Fore.RESET}"{title}"')
except AttributeError:
continue
continue
except IndexError:
return
if len(self.files_url) < 10:
self.print_info()
self.path.parent.mkdir(exist_ok=True)
self.path.mkdir(exist_ok=True)
print("")
with ThreadPoolExecutor(max_workers=10) as executor:
for file in self.files_url:
tt = file.split("\n")[0].strip()
url = file.split("\n")[1].strip()
self.files.add(tt)
executor.submit(self.get_file, url=url, title=tt)
self.files_url.clear()
self.print_info()
print(f'{Fore.GREEN}Затрачено времени {Fore.RESET}| '
f'{(int(time.monotonic() - time_start) // 3600) % 24:d} ч. '
f'{(int(time.monotonic() - time_start) // 60) % 60:02d} м. '
f'{int(time.monotonic() - time_start) % 60:02d} с.\n')
def menu(link: str):
"""
Создание меню для навигации с помощью клавиш. Создание экземпляра класса
в соответствии с выбранными параметрами. Запуск получения постов группы и
скачивания вложений, если таковые имеются.
:param link: Ссылка на группу или экранное имя.
"""
try:
ext = []
img = ["psd", "jpg", "jpeg", "png", "gif", "tiff", "ico", "svg", "webp", "bmp"]
doc = ["pdf", "odt", "ods", "doc", "docx", "xls", "xlsx", "fb2", "mobi", "epub", "djvu", "djv", "zip", "rar",
"tar"]
pls = ["m3u", "m3u8"]
subprocess.call("clear", shell=True)
print(f'{Fore.GREEN}Выбор формата вложений для загрузки\n{"-" * 25}\n')
opt = ["1.Изображения", "2.Документы", "3.Плейлисты", "4.Все форматы", "5.Выход"]
ch = TerminalMenu(opt).show()
if opt[ch] == "1.Изображения":
attach = VKAttach(link, img)
attach.get_posts()
elif opt[ch] == "2.Документы":
attach = VKAttach(link, doc)
attach.get_posts()
elif opt[ch] == "3.Плейлисты":
attach = VKAttach(link, pls)
attach.get_posts()
elif opt[ch] == "4.Все форматы":
ext.extend(img)
ext.extend(doc)
ext.extend(pls)
attach = VKAttach(link, ext)
attach.get_posts()
elif opt[ch] == "5.Выход":
raise KeyboardInterrupt
except (KeyboardInterrupt, TypeError):
subprocess.call("clear", shell=True)
print(f"\n{Fore.GREEN}Good By!\n")
sys.exit(0)
def main():
"""
Запрос у пользователя ссылки на группу.
Запуск создания меню выбора дальнейших действий.
"""
link = input(Fore.RESET + "\nВведите ссылку на группу: ")
menu(link)
if __name__ == "__main__":
main()Вот скриншоты работы. Для начала вводим ссылку на группу.
Затем выбираем в меню, какой тип вложений мы хотим скачивать.
Ну и, собственно, сам процесс загрузки, вернее его начало.
Ну, а это еще один скрин, уже из другой группы. На нем видно, что во всех постах группы найдено всего 8 вложений. И все они будут скачаны.
А на это, пожалуй, все.
Спасибо за внимание. Надеюсь, данная информация будет для вас полезна
Ссылка на код скрипта в GitHub